
Pourquoi le Parquet existe-t-il ?
Le format Parquet a été créé pour répondre aux besoins de requêtes fréquentes sur Hadoop (sucesseur de Trevni). Le format colonnaire tel que Parquet résout certaines limitations des formats de données dits “traditionnels” comme le CSV. En tant que format de stockage orienté colonne, Parquet permet une lecture plus efficace des données lorsqu’on ne cible que certaines colonnes spécifiques, ce qui optimise les performances des requêtes analytiques.
Format Ligne vs. Format Colonne : Quelle différence ?
– Format Ligne tel que CSV, nécessite la lecture complète de chaque ligne pour accéder à une colonne spécifique, entraînant des pertes de temps et de performance.
– Format Colonne comme Parquet permet d’accéder directement aux colonnes ciblées, réduisant ainsi le volume de données scannées et améliorant la vitesse de traitement.
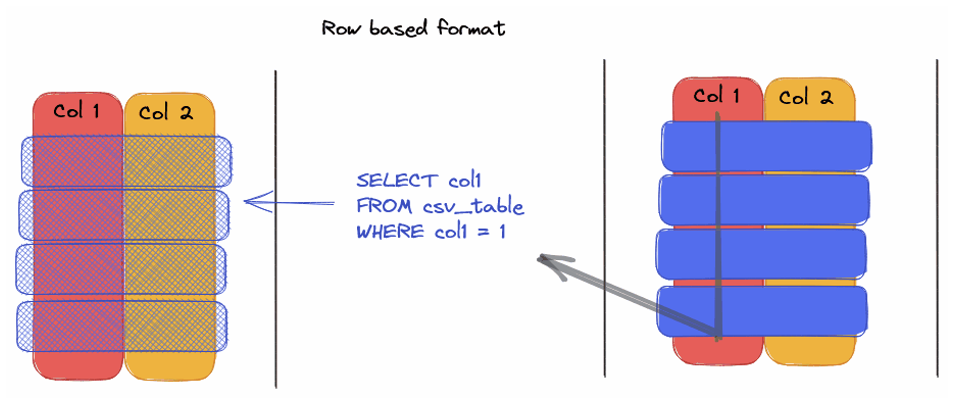
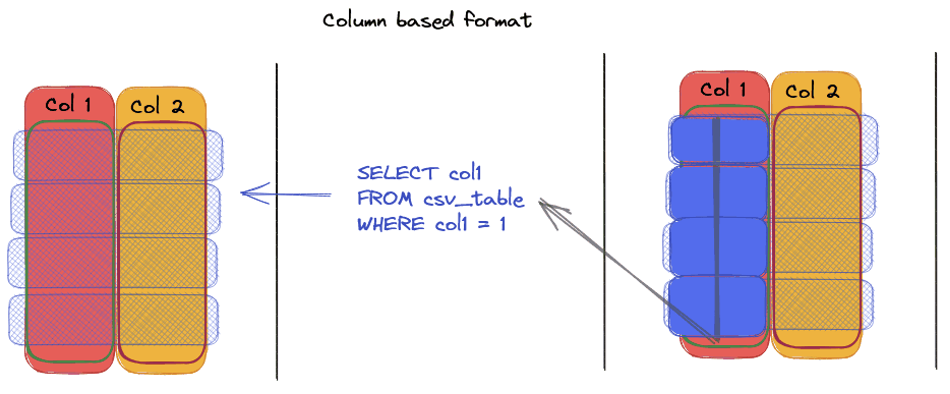
Les atouts de Parquet par rapport au CSV
– Typage des données : Parquet stocke les types de données directement dans les métadonnées, facilitant la gestion des types
– Compression des données : Prend en charge plusieurs algorithmes (Snappy, Gzip, etc.), offrant des gains d’espace considérables (jusqu’à 87 % de réduction en stockage)
– Data Encoding : Utilise des techniques comme le Dictionary Encoding pour optimiser le stockage des valeurs répétitives.
– Lecture/Écriture parallèle : Compatible avec des systèmes distribués comme Apache Spark, permettant un traitement plus rapide des fichiers massifs.
– Métadonnées enrichies : Parquetstocke des statistiques avancées permettant des optimisations lors des requêtes.

Cas d’utilisation concret avec AWS Athena
 Lors de tests comparatifs sur AWS Athena, Parquet a démontré :
Lors de tests comparatifs sur AWS Athena, Parquet a démontré :
– Gain d’espace : Un dataset de 1 To en CSV réduit à 130 Go en Parquet, soit 87% de gain
– Amélioration de la vitesse : Requête SQL passant de 236 secondes (CSV) à 6,78 secondes (Parquet), 34 x plus rapide
– Réduction des coûts : De 5,75 € en CSV à 0,01 € en Parquet grâce à la réduction des données scannées. Une réduction de ~99%.
Source : https://www.linkedin.com/pulse/difference-between-parquet-csv-emad-yowakim/
Pro Tip : Pensez à aggréger/coallesce pour minimiser le nombre de fichiers pas trop volumineux (< 1GB)
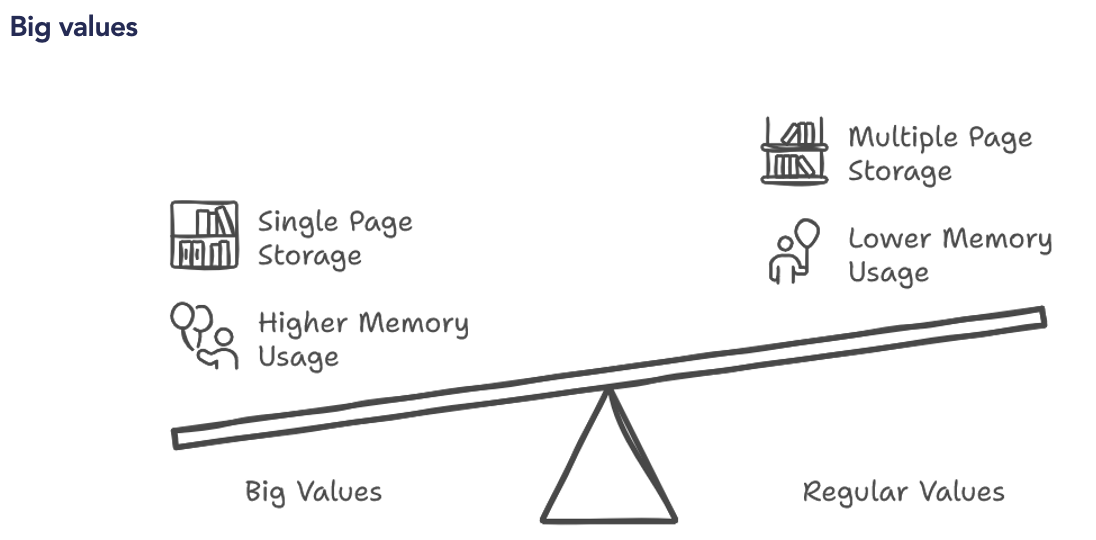
Les limites du format Parquet dans le Machine Learning
– Non adapté aux données non structurées : Parquet n’est pas idéal pour stocker des modèles ML ou des données non structurées (images, vidéos)
– Problèmes lors de l’écriture massive : Nécessite de charger toutes les données en RAM avant l’écriture, ce qui peut être limitant pour les gros modèles.
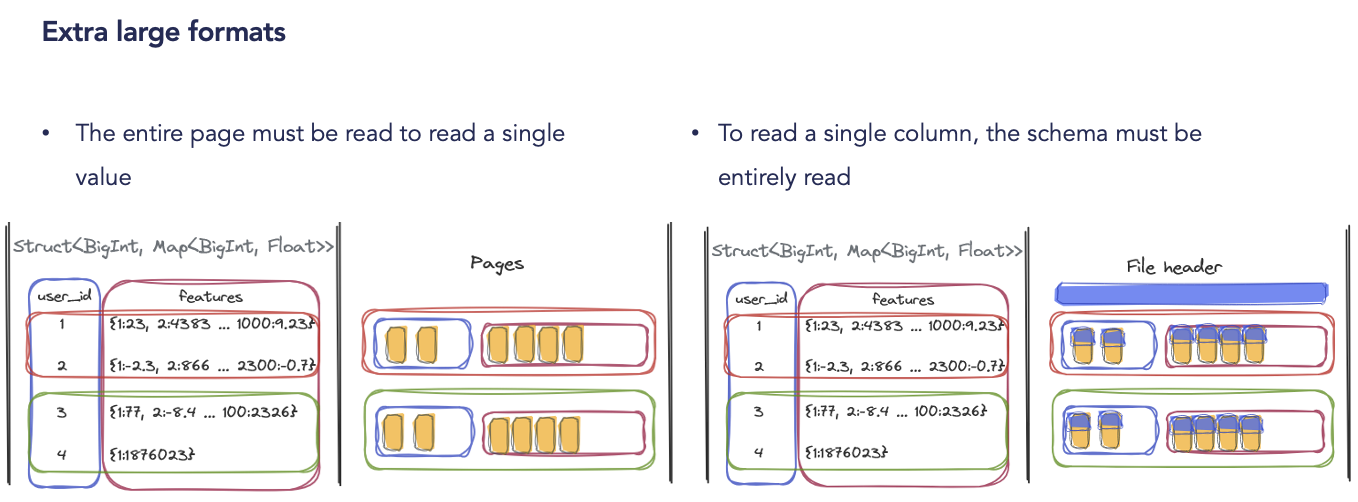
Les alternatives modernes : Lance et Nimble
– Lance (LanceDB) : Propose une version améliorée de Parquet, éliminant les row groups pour des performances de lecture jusqu’à 2000 fois supérieures.
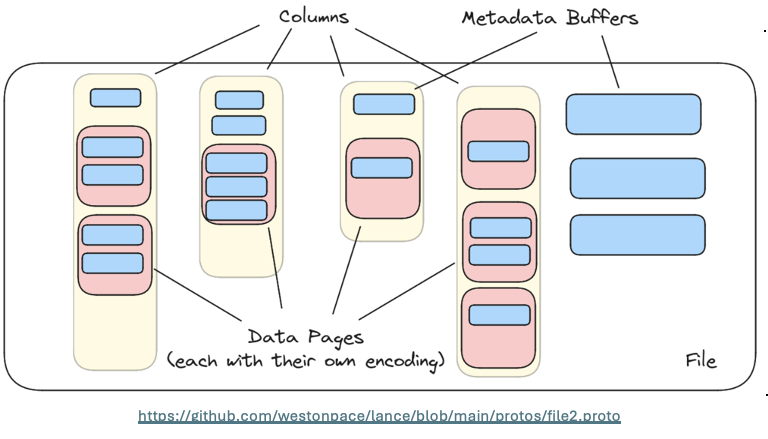
– Nimble (Meta) : Optimise le format ORC (alternative à Parquet) en centralisant les métadonnées (footers au lieu des headers en Parquet) et en changeant la façon de définir ces métadonnées, offrant ainsi des gains en vitesse d’accès.
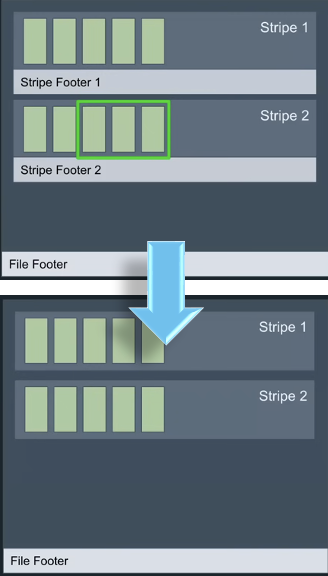
Le format Parquet s’impose comme un choix incontournable pour le stockage de données analytiques, notamment grâce à ses avantages en matière de compression, de typage des données et de performances SQL. Toutefois, pour les cas d’utilisation en machine learning ou sur des données non structurées, de nouvelles alternatives comme Lance et Nimble émergent, offrant de meilleures performances.
Recent Comments