With the rise of interest and the number of machine learning projects (self-driving car, facial recognition, recommendation systems), traditional software development has shifted from hard-coded rules to data-estimated rules a.k.a. data-driven models (cf. figure 1). A set of new challenges arose for building reliable and stable information systems that rely on imperfect data-driven models, such as model versioning, deployment, monitoring, explainability and reproducibility..
By Samson ZHANG, Data Scientist at LittleBigCode
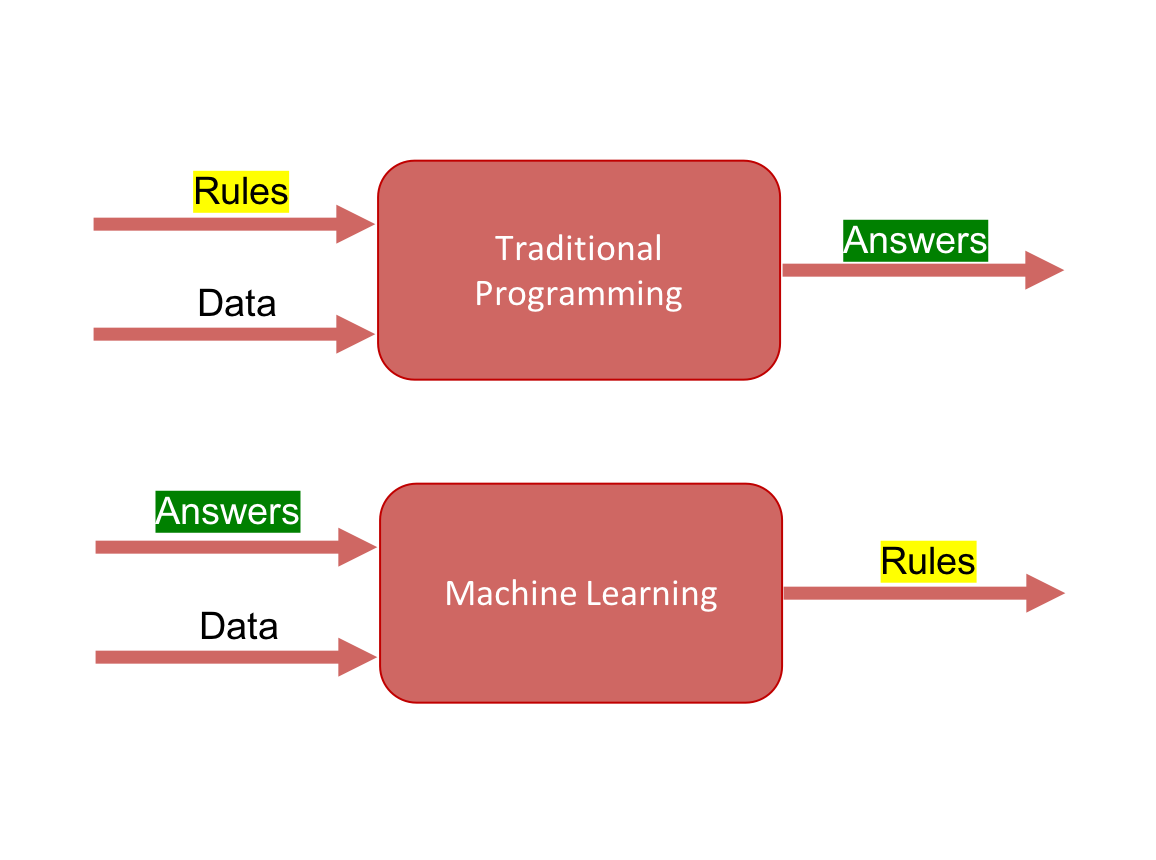
Figure 1. Machine learning vs traditional software development. Source : http://datalya.com
There is a whole new set of software engineering best practices that comes with the use of data-driven models in order to tackle those challenges, called MLOps. In order to get a broader view of what MLOps is, I recommend you to take a look at Jamila Rejeb’s article: Why MLOps is so important to understand ? The main purpose of MLOps is to make your entire ML project lifecycle automated and reproducible. In this article, we will mainly focus on data & model experiment tracking/versioning. The main issues data & model experiment tracking aim to solve are :
-
Code reproducibility
-
Data set reproducibility
-
Artifacts logging (model weights, hyper-parameters)
-
Experiments’ results comparison
A data-driven model is, by definition, a model that learns from data (cf. figure 2). It means that talking about model versioning, does not only involve versioning the code/algorithm (neural networks, trees, etc…) and its different parameters (weights, etc…). It also involves versioning the data used for training the latter, as in practice, the data set can change which impacts the model’s performance. Model versioning makes model reproducible in different environments and makes collaboration easier.
Being able to reproduce your models does not only benefit you. In some instances, it can also prevent you from legal issues where you would need to prove ownership of the models by showing that you can generate your models from end to end.
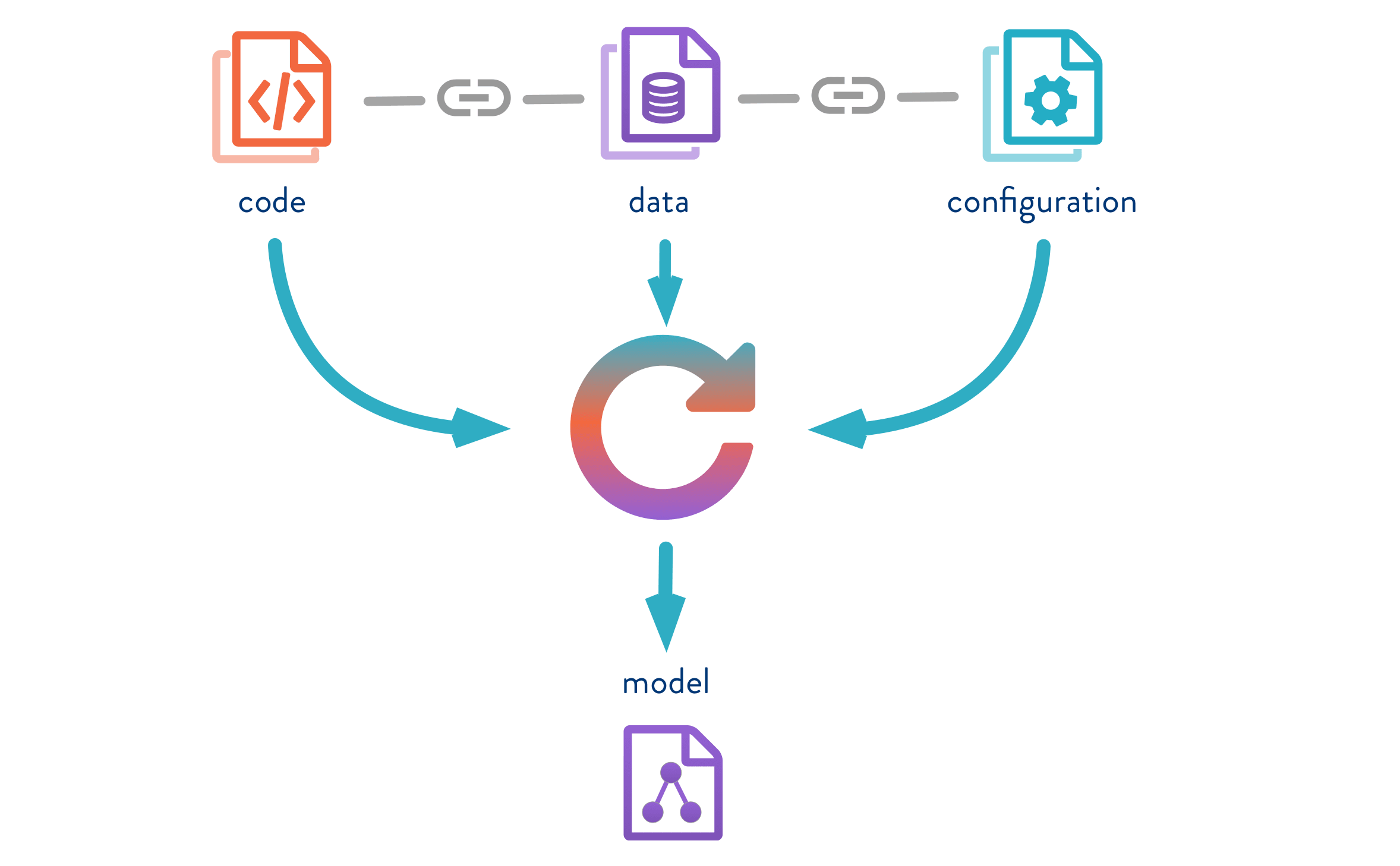
Figure 2. What is a data-driven model. Source : http://dvc.org
Why do we even need to track our model experiments ?
Traditional software engineering keeps track of the logic and rules of systems by versioning their code, which is easily doable with tools such as Git. As machine learning projects integrates data-driven models into traditional information systems to replace the hard-coded logic, one could want to version models for the same reasons.
For some businesses, data-driven models have become the core of their systems and are entirely reliant on the performance of those models. The success of the companies may rely on their ability to improve their models in order to scale up.
When data-driven models are this important to the success of a project, they also define the capability and the limits of the system. For complex algorithms / models, one may want to explore a new promising path with many experiments in order to improve existing models, but one could also need to roll back if the exploration gives nothing. Even more, one can be interested in reusing a part of an experiment and combining it with other new algorithm features. It can become easy to lose track of your past experiments if not well-managed. These experiments are time-consuming and cost-expensive (complex models such as GANs can take entire weeks to train for a single set of hyper-parameters), so you would want to be able to track your experiments and to reproduce the models from scratch if necessary.
Is not just tracking the best-performing model enough ?
As any experienced scientist would tell you, the methodology is important and keeping track of the experiments’ parameters and results is fundamental. As a data scientist, you must not only do data exploration and just keep the best model trained. You must and need to keep track of all your model experiments. Knowing what training settings do not yield the best results is as important as keeping the best model that is used in production. Like traditional software engineering, the experiments history helps your team members and you remember what has been done, especially when you have many experiment configurations and try to remember them 6 months later. It tells you what settings you already tried and allows you not to repeat failed/unpromising experiments, thus, saving time and money.
Desirable features and tools
Experimenting with training machine learning models, I found that running a training loop and saving the final weights is the easiest part when doing model search as long as you do not need to look back at your experiment and your code, which frankly never happens. When looking back at model experiments, what I want to be able to recall is how the models are created and trained, with what data and environment (dependencies, hardware), be able to compare different runs and retrieve the best performing models based on metrics evaluated on a hold-out data set, ideally with an intuitive user interface.
In order to do that, we will use Git, MFlow and DVC.
Summary of features :
|
git |
GNU 2.0 |
X |
X |
local |
X |
X |
X |
|
X |
|
|
|
mlflow |
Apache 2.0 |
X |
|
local, cloud |
X |
X |
|
X |
X |
|
X |
|
dvc |
Apache 2.0 |
X |
X |
local |
X |
X |
|
|
|
X |
|
All three tools are free, open-source and complement each other in order to provide a complete model experiment tracking experience.
Many tools exist for model experiment tracking but we will explore two of them, free and open-source, that are complementing Git versioning tool well:
-
MLflow GitHub – mlflow/mlflow: Open source platform for the machine learning lifecycle for experiments tracking (code version, hyper-parameters, metrics, plots). It has a REST API and good graphical UI.
-
Data Version Control (DVC) GitHub – iterative/dvc: 🦉Data Version Control | Git for Data & Models | ML Experiments Management for data set versioning. The “Git for data”. It is particularly suited for data sets with a large number of files such as image data sets.
The other MLOps subjects will be addressed in future articles.
We choose MLflow and DVC because when it comes to open-source experiment tracking, MLFlow and DVC are among the most popular tools with respectively 167M downloads/11.2k stars/360+ contributors and 9.2k stars/240+ contributors. They have been adopted by many teams working in both big and small companies and their communities are huge. It provides a sense of security that Mlflow and DVC will continue to develop and be used for many years to come.
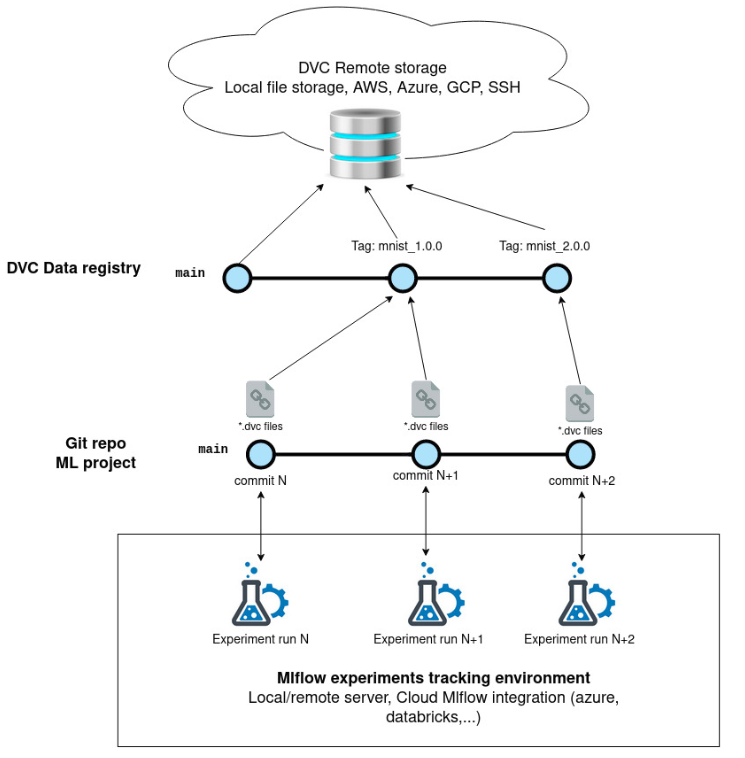
Figure 3. Mlflow experiments and DVC data sets are all linked to Git commits
Mlflow and DVC provide you a complete model experiment tracking experience.
They help you :
- Centralize your data
- Reduce your data storage cost by not duplicating sata
- Share your experiments with your collaborators
All you need to look at are git commits. From any of your git commit hash, you can find all the information concerning your model experiment :
- The data set used tracked by *.dvc files in your commit
- The training parameters, metrics, model weights logged by Mlflow (Mlflow also logs the commit hash for reverse search)
We can use the Mlflow tag “tags.mlflow.source.git.commit” to search the corresponding experiment (through mlflow ui or any other mlflow API) (cf. figure 4)

Figure 4. Experiment run search by git commit hash in Mlfow UI
Usually we would want to look at the data set and model used that produced a certain result logged by Mlflow. In this case, the git commit hash can be found in the experiment run’s tags. From this you can just checkout your git repository and DVC-tracked data sets.
Conclusion
Training data-driven models can be expensive (time and money). Automatically versioning your data sets and model experiments helps you :
• Centralize your experiments
• Share your experiments’ results
• Reproduce your models
• Avoid repeating failed experiments
In this article, you got an explanation of the purpose of model and data tracking for machine learning projects and a brief overview of how some tools like DVC (for data set tracking) and Mlflow (training experiment tracking) can help solve this challenge.
This article belongs to a series of articles about MLOps tools and practices for data and model experiment tracking. Four articles are published :
PART 1 (this article) : Introduction to data &; model experiment tracking
PART 2 (click here) : MLOps: How DVC smartly manages your data sets for training your machine learning models on top of Git ?
PART 3 (soon available) : MLOps: How MLflow effortlessly tracks your experiments and helps you compare them ?
PART 4 (soon available) : Use case: Effortlessly track your model experiments with DVC and MLflow
Feel free to jump to other articles if you are already familiar with the concepts !