Nowadays, diversity is the holy grail of model accuracy: deep forest is a promising framework based on deep learning layers but without neurons and back propagation. The revolutionary deep forest frameworks enable the introduction of diversity as the tip of the iceberg. The following article will present the framework and diversity, as well as demonstrate how to apply your diverse ensemble models to this novel framework.
By Simon PROVOST, Data Engineer at LittleBigCode

While ensemble approaches give excellent results nowadays, Zhi-Hua Zhou and Ji Feng indicate in their work on a novel deep learning methodology that where a random forest produces decent results on your data, apply a deep forest and you will be pleasantly surprised. The proposal by Zhi-Hua Zhou and Ji Feng of a revolutionary deep learning framework dubbed Deep Forest (DF) can be considered as one of the most significant events in machine learning in 2017.
The DF employs a number of ensemble-based approaches, most notably Random Forests (RF) and Stacking, to generate a structure similar to that of a multi-layer neural network, except that each layer is made of RFs rather than neurons. DF is particularly favourable for training because it requires a small number of hyperparameters, does not require back-propagation, and outperforms some well-known techniques, including deep neural networks, when only small-scale training data is available` [1, 2].
Diversity enhancement is a technique that entails combining numerous « weak » or “weak”/”performant” learners into a single « strong » learner, with « weak » being relative. As a result, the stacking theory should minimise both bias and variation, and it is particularly effective at avoiding overfitting and variance. This is because of two reasons :
-
Each ensemble learner will have a somewhat different manner of mapping features to outcomes, and the idea is that by combining them, a larger portion of the search area will be covered.
-
Furthermore, taking the first and second models of an ensemble, both have a low bias but a high variance owing to overfitting, they have theoretically overfitted separate regions of the search space; after combining them, the overall variance would be reduced.
As a consequence, ensemble learning with a focus on diversity (i.e., choose your learners carefully) will result in a reduction in overall variance. Additionally, in practice, this is commonly added to ensemble by injecting randomness during training [11 – Section IV-B].
Because I believe that the diversity of our models is the next breakthrough among others in machine learning, here is a more general description of how the DF includes diversity management and why it is critical in machine learning, or more precisely, ensemble approaches and stacking.
The following article begins with an overview of how DF function, followed by a brief explanation of why diversity is important in DF, and then a quick introduction on how to enhance diversity with the DF framework (practically perspective).
How does the Deep Forest function in general ?
Because the original paper states it very effectively and succinctly, the following explanation will be broad in scope; consequently, for the mathematical component, refer to the original papers as well [1, 2]. Consequently, we will analyse the classification and prediction components of the Deep Forest architecture using the diagram below :
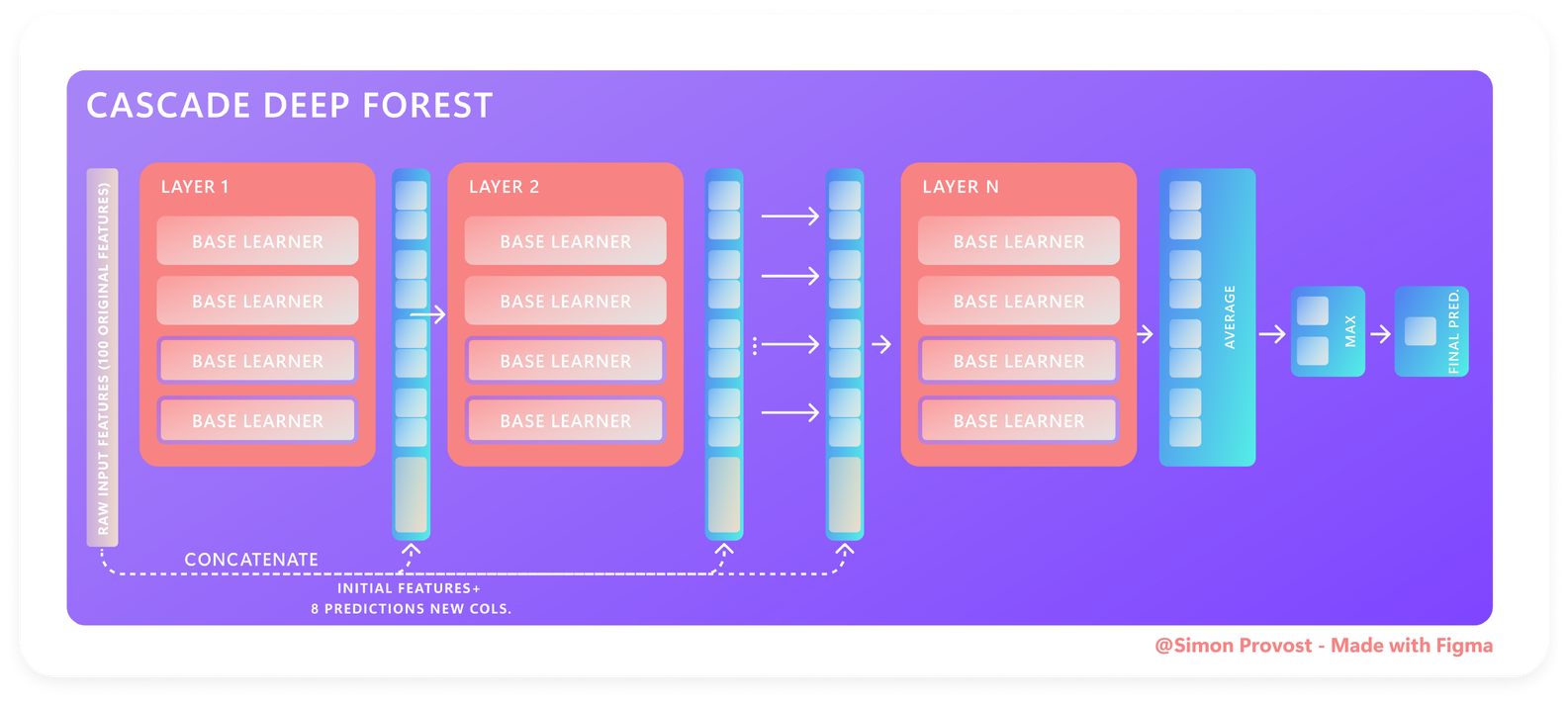
Layer by layer, here’s how Deep Forest Architecture works :
- The first layer is supplied with the initial raw vector of features, and then
nestimators previously configured are executed, each of which produces prediction vector (i.e., binary class classification: two outputs, multi-class classification:n_classoutputs). - The prediction vectors are concatenated to the second layer’s input along with the initial raw vector, which naturally increases the dimensionality of features with each subsequent layer, and so forth.
- Penultimately an average of each layer’s results is determined;
- And finally, a max function is output in order to obtain the final prediction.
Nota bene : While the preceding processes are automated, the first step can be performed manually or automatically using the default ensemble combination specified by the framework’s designers. To do so manually, read the remainder of this article to learn how to do so.
How does diversity is applied in Deep Forest ?
Diversity is a vast subject of study, and here we will discuss how an engineer should think while selecting his base learners (i.e., algorithms). Following which, we will conclude by showing how these three techniques apply « diversity » :
- The first methods appear to follow what random forest uses; notably, sample-based. This technique apply diversity on a sample-by-sample basis, which implies that each model in the ensemble will search in a different part of the overall space of the data and therefore cover the entire data more effectively.
- Hyper parameter-based methods, which tend to say that it is better to optimise the model directly rather than combining precised algorithms, to increase the diversity’s results improvement; thus, each model has an objective function based on a variety of measurements chosen, and practitioners should modify the hyper parameter to achieve the objective function, so that the overall results would be diversified in an hyper parameter perspective.
- Finally, ranking-based methods, which entail taking a list of learners (diversified or not), ranking them according to diversity criteria this time, and selecting the L one as your final model (e.g., The clustered-based method involves plotting the model’s results in a two-dimensional space and clustering [automatically or not] them to extract only those that correlate for the given criterion).
As a result, depending on the approach used to select learners for the ensemble, the diversity will be applied differently, depending on whether the view is sample-based, hyperparameter-based, or algorithm-based. Finally, the DF will be used in the final perspective when your ensemble learners are averaged to make one, at which point the diversity will be applied to the findings of the learners you previously selected using the brief techniques outlined above. To learn more, consult this scholarly article [11].
Why diversity in Deep Forest ?
Due to the DF theory’s primary focus on ensemble and stacking, diversity is another key component included in the package. However, why is it such a critical component of the framework?
What is an Ensemble learning and the Bagging/Boosting and Stacking sub-paradigms ?
From the gcForest to Deep Forest paper updated in 2019 [2]: `Ensemble learning [4] is a machine-learning paradigm in which a task is solved by training and combining several learners (e.g. classifiers). […]` Therefore, among the ensemble learning methods we have :
- Bagging which frequently considers homogeneous weak learners, learns them independently from one another in parallel, and then combines them using a deterministic averaging process;
- Boosting which frequently considers homogeneous weak learners, learns them sequentially in a highly adaptative manner (a base model depends on the previous ones), and then combines them using a deterministic strategy; and finally;
- Stacking, on the other hand, frequently considers heterogeneous weak learners, learns them in parallel and aggregate them by training a meta-model to generate a prediction based on the output of the many weak models.
Why does diversity has to deal with stacking ensemble ?
Due to the heterogeneous manner in which stacking occurs, diversity plays a critical part in allowing this. As briefly mentioned previously in the article, diversity enables the development of robust ensemble models; this is also stated in the DF original paper: `[…] “to build a strong ensemble, the individual learners must be precise and different”.
Combining purely correct learners is frequently inferior than combining some accurate learners with some comparatively weaker learners, since complementarity takes precedence over pure accuracy.`[2]. Nonetheless, scientists continue to grapple with the same enigma: ‘What is diversity really?’ This question remains the field’s holy grail.
Finally, because diversity is a critical component of the DF framework, its lead engineer states in [5] that the framework contains diversity by default and has the capability to incorporate diversity into the learning process, allowing the user to completely customise it to their liking. As a result, the following section will discuss how to use the Deep Forest framework, formerly known as gcForest, to deal with diversity, which is sometimes referred to in the literature as ambiguity.
Deep Forest (DF) installation
We presume below that you already have Python installed because deep forest is a Python framework; otherwise, please see the python / pip manual for information on how to install them. [6, 7] To install the Deep Forest 21 Framework, follow the steps below :
DF Cascade Forest Classifier Using its own estimator
The following example explains how to override the default estimator with your own. This could be for a variety of reasons, including: first, the desire to explore classifiers other than the default one to improve your diversity ensemble; secondly, the desire to explore with a custom Scikit learn forked classifier (i.e., your custom classifier). Assume I want to design a DF model that uses an RUSBoost classifier [8] and a random forest [9] as its estimators. Additionally to that about diversity, I will just replicate what the original paper use, but instead of allowing the framework to do so by default, I will utilise an ExtraTreesClassifier directly from its library’s implementation [10]. Nota bene : this is totally subjective; you may choose any base learner and any classifier that increases diversity you wish; I chose them at random above solely for the sake of illustration: (1) Instantiate your deep forest estimators; if this one requires additional estimator, you may combine them as follows :
(2) Apply the estimators which is composed of your individuals classifier accompanied with some that will help the diversity during the training, and this N time (I.e., here N has to be chosen, see below) :
Finally, you can perform your configuration by calling the usual fit predict/predict probability functions, and will provide the possibility to display as usual, the classification report; confusion matrix ; or/and feature importances map of your model using a custom configuration derived from the default one.
Discussion / Conclusion
Diversity is not a set of instructions to follow, such as how to install software; rather, it is a greater understanding of how combining two to N learners increases the likelihood of achieving high predictive accuracy on your current real-world situation. As a result of the release of Deep Forest in 2017, here is a fast tutorial to help you learn and understand how to use the framework’s diversity feature.
Now that you understand how to perform the procedure of running its own learner(s) using Deep Forest, let’s road your data and model using Deep Forest as well as enhance its diversity for the purpose of your machine learning case. Finally, for a more in-depth examination of machine learning diversity, see [11] and the original deep forest papers [1]. I hope this has clarified why diversity is important and how simple it is to implement using the architecture outlined above. Start using it now, and let us know what you think and how you would change it in the comments section below.
Additionaly, I have already published an article devoted to this innovative DF technique applied to medical-data [3].
References
[1] Z.-H. Zhou and J. Feng, “Deep forest,” arXiv preprint arXiv:1702.08835, 2017.
[2] Z.-H. Zhou and J. Feng, “Deep forest,” National Science Review, vol. 6, no. 1, pp. 74– 86, 2019.
[3] Michele L, Provost S, Julien L, Sauer M, Chaptinel M., Classification of Sleep-Wake states with the use of a novel Deep-Learning approach. Medium, Awake’s organisation (2021). Available at : Classification of Sleep-Wake states with the use of a novel Deep-Learning approach [Accessed 10 December 2021].
[4] Zhou ZH. Ensemble Methods: Foundations and Algorithms. Boca Raton, FL: CRC Press, 2012.
[5] Xu, Y., 2021. [Question] n_estimators how does it works? · Issue #100 · LAMDA-NJU/Deep-Forest. [online] LAMDA-NJU/Deep-Forest. Available at : [Question] n_estimators how does it works? · Issue #100 · LAMDA-NJU/Deep-Forest [Accessed 10 December 2021].
[6] Python., 2021. Download Python. [online] Python.org. Available at : Download Python [Accessed 10 December 2021].
[7] Python Packaging User Guide — Python Packaging User Guide . 2021. Installing Packages — Python Packaging User Guide. [online] Available at : https://packaging.python.org/en/latest/tutorials/installing-packages [Accessed 10 December 2021].
[8] Seiffert, C., Khoshgoftaar, T., Van Hulse, J. and Napolitano, A., 2008. RUSBoost: Improving classification performance when training data is skewed. 2008 19th International Conference on Pattern Recognition,.
[9] Breiman, L., 2001. Machine Learning, 45(1), pp.5–32.
[10] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, D., Brucher, M., Perrot, M., and Duchesnay, E. 2011. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, p.2825–2830.
[11] Z. Gong, P. Zhong and W. Hu, “Diversity in Machine Learning,” in IEEE Access, vol. 7, pp. 64323–64350, 2019, doi: 10.1109/ACCESS.2019.2917620.