Lorsqu’ils développent leur modèle, les data scientists sont souvent confrontés à certaines difficultés pour suivre leurs expériences, en créer de nouvelles, conserver l’ensemble des informations liées à chacune d’elles… Un constat partagé dès lors qu’il s’agit de créer également les ressources nécessaires pour exécuter les tâches de préparation (gathering, validation) et de traitement des données (pre-processing, training, prédiction). C’est là que l’utilisation de Kubeflow s’avère pertinente. Et on vous explique pourquoi dans cet article.
Par Thomas DUNGLAS, Data Engineer chez LittleBigCode
En effet, Kubeflow est un outil intéressant pour faciliter et fluidifier l’expérimentation en data science. Pourquoi ? Parce qu’il rend le processus plus automatique, et permet de versionner et de monitorer les modèles ainsi produits. Kubeflow a notamment pour avantage de s’exécuter sur un cluster Kubernetes, ce qui le rend particulièrement performant, et facilite la réalisation d’expériences et l’amélioration en continu des modèles et des algorithmes.
En revanche, son utilisation peut s’avérer complexe et parfois lourde. Par exemple, lors d’un démarrage, il est nécessaire d’avoir à disposition un cluster Kubernetes, ce qui n’est pas toujours le cas en phase de développement. Dans la suite de cet article, nous vous présenterons alors comment fonctionne cet outil et comment vous pouvez réaliser des tests en local sans avoir besoin de créer un cluster Kubernetes coûteux sur un cloud provider.
Dans quel contexte utiliser Kubernetes ?
En tant que data scientist, on souhaite entraîner des modèles de machine learning de façon rapide et efficace. Pour cela, on a souvent recourt à l’outil Kubernetes, un moteur d’orchestration de conteneurs qui permet d’automatiser le déploiement, la scalabilité et la gestion d’application conteneurisées.
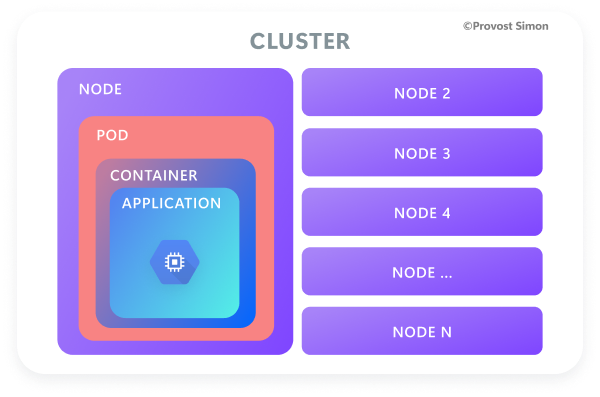
Kubernetes permet de simplifier l’exécution d’application sur un cluster composé d’un ensemble de serveurs appelés nodes. Ces applications sont packagées sous la forme d’images de conteneur, incluant l’application elle-même ainsi que toutes les dépendances nécessaires (package Python, librairies systèmes, configuration…).
Or l’exécution et la planification des conteneurs sur des machines physiques ou virtuelles nécessite la création de composants (nodes, pods, services…), ce qui n’est pas le principal souci des data scientists. Par conséquent, pour faciliter l’utilisation de Kubernetes sans forcer les data scientists à maîtriser ces étapes de configuration, nous avons donc décidé d’utiliser Kubeflow.
Pourquoi utiliser Kubeflow
Kubeflow est un projet open source regroupant un ensemble d’outils dédiés au machine learning et conçu pour être exécuté sur un cluster Kubernetes.
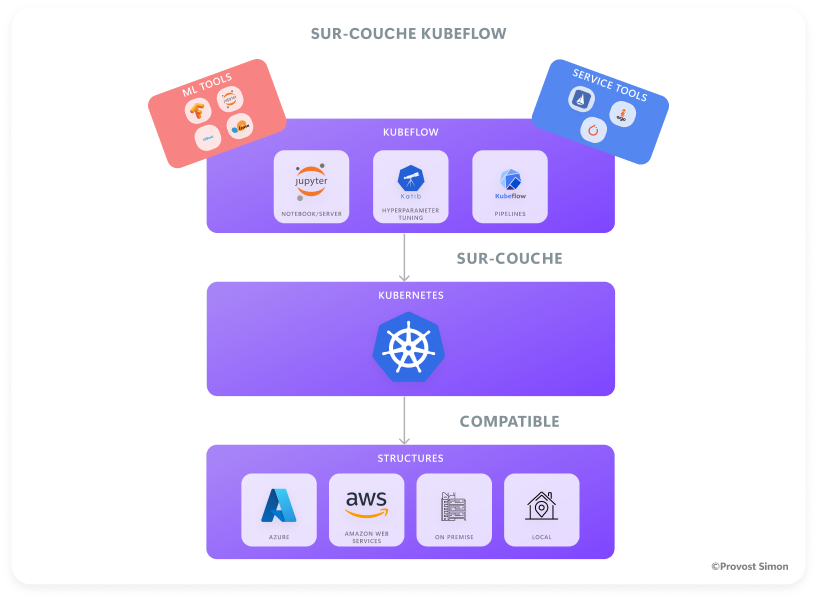
En tant qu’outil d’orchestration de tâches et de workflow, Kubeflow se démarque de ses concurrents par :
-
L’écriture des tâches est compatible cross-langage : Python et YAML sont actuellement supportés.
-
La centralisation de l’outil sur le déploiement de pipelines permettant de traiter les données, d’entraîner des modèles et de déployer la solution :
o Chaque étape est isolée dans son conteneur (par exemple : grande personnalisation) ;
o Interface utilisateur performante ;
o Fiable (par exemple : peu de plantage).
-
Le regroupement de runs dans des expériences.
-
Le versionning des runs[1].
-
L’exécution simple et récurrente de runs.
-
Une interface graphique et des outils simples permettant de s’abstraire de Kubernetes.
Comment utiliser Kubeflow en local
Dans un premier temps, nous allons devoir d’installer un gestionnaire de conteneurs (Docker dans notre cas), un cluster Kubernetes local grâce à Kind et, enfin, l’outil en ligne de commande kubectl pour s’interfacer avec le cluster. Nous allons également installer brew pour faciliter les installations sur Mac.
L’objectif avec Kubeflow en local est de tester et de mettre en place une pipeline permettant l’entraînement de modèles de machines learning sans créer de ressources sur un cloud pour éviter des frais d’utilisation du cluster Kubernetes.
Kubeflow Pipelines, lors de l’installation de tous les composants, occupe au moins 24 Go d’espace, donc attention à certaines erreurs lors de la création des pods qui peuvent ne pas s’instancier correctement à cause d’un manque d’espace disponible (Nota Bene : la machine sur laquelle j’ai testé cette solution avait 8 Go de RAM, 4 CPU et 80 Go de mémoire disponible).
2.1/ Installer Docker
J’ai installé Docker en suivant les instructions de la documentation Docker (cf. référence ci-dessous) avec le gestionnaire de paquets apt pour ma machine Ubuntu :

Pour des distributions Linus différentes :

Référence : ![]() Install Docker Engine on Ubuntu
Install Docker Engine on Ubuntu
2.2/ Installer kubectl
Pour Linux, j’ai utilisé la commande :
-
curl pour la requête url ;
-
LO pour suivre la redirection et nommer ce qui va être téléchargé par le même nom (le fichier kubectl sera téléchargé et gardera son nom) ;
-
S pour mode silencieux.
Après, j’ai vérifié le binaire kubectl avant de l’ajouter à mon $PATH.
Référence Linux : ![]() Install and Set Up kubectl on Linux
Install and Set Up kubectl on Linux
Pour Mac, il est possible d’utiliser brew avec l’une des deux commandes :

Référence Mac : ![]() Install and Set Up kubectl on macOS
Install and Set Up kubectl on macOS
Pour vérifier que kubectl est bien installé et présent dans le $PATH :
Kubernetes, une fois installé, nous permet d’utiliser sa commande cli kubectl pour interroger facilement l’état de son cluster et des ressources associées.
2.3/ Mettre en place une pipeline dans Kubeflow
2.3.1. Installer Kind
Pour Linux :

Voici la procédure associée :
-
Récupérer le binaire ;
-
Changer ses permissions ;
-
Et l’ajouter dans le path.
Référence : kind – Quick Start
Kind va permettre de mettre en place un cluster Kubernetes en local sans engendrer les coûts que l’on aurait pu avoir avec l’utilisation d’un cluster hébergé sur un cloud provider.
2.3.2. Créer un cluster kind en local
Avec le binaire de kind, on peut utiliser la commande kind pour créer un cluster :

Le cluster cluster_name peut être vérifié avec les commandes suivantes :

La création du cluster peut engendrer une erreur comme :

Une solution possible pour résoudre ce problème est d’ajouter l’utilisateur en cours (nous) dans les permissions du groupe de Docker :

-
usermod -asignifie ajouter un nouvel élément dans le groupe mentionné par-G
Ensuite, il est nécessaire de redémarrer pour que le changement soit pris en compte.
Le cluster peut aussi être visible par une url donnée dans le terminal. Si une erreur Kubernetes-error-code-403 apparaît sur cette page, celle-ci est due à un manque de droit / rôle pour un utilisateur précis.

-
clusterrolebinding est une liaison qui définit un rôle associé à un utilisateur pour un cluster.
La commande devrait résoudre le problème pour l’adresse 127.0.0.1 : port visible par le terminal.
Figure : Cluster local
Cependant, le core dns est probablement encore en erreur sur le lien suivant car, à cet emplacement, il n’existe pas.
– Une solution alternative pour accéder au cluster sur la page web sans mettre en place de rolebinding consiste à lancer un proxy avec kubectl :

2.3.3. Installer les composants Kubeflow pour Kubeflow Pipelines
Maintenant que le cluster Kubernetes est installé en local, on peut utiliser la surcouche Kubeflow pour mettre en place sa caractéristique principale en place : le pipeline.
Voici les commandes à exécuter :

La dernière version stable à ce jour était 1.7.0 pour le pipeline.
-
Kubectl applycommande pour modifier / créer de nouvelles ressources Kubernetes définies à partir d’un fichier manifest ; -
-kpour définir le chemin du fichier kustomization à utiliser (par exemple : créer un flux sur les fichiers de configuration dans son emplacement avec une étiquette définie dans le fichier kustomize) ; -
wait --for condition=en attente pour une condition spécifique ou une ou plusieurs ressources.
Les commandes à exécuter reposaient sur un export afin de définir la version de pipeline à utiliser, puis sur une suite de kubectl apply afin de créer les ressources décrites dans les fichiers de kustomization :
-
Le premier apply : créer les ressources de cluster-scoped-ressources qui sont des ressources sans espace de nom mais reliées directement au cluster.
-
Le deuxième apply : créer les ressources de platform-agnostic-pns (par exemple : process name sharing) qui seront visibles par les autres containers dans le même pod.
-
Le wait attend que l’application installée (kind) est bien installée sur le cluster local.
-
Après le dernier apply, les ressources sont chargées mais pas encore prêtes, le processus prend plusieurs minutes (10 minutes environ).
Pour vérifier si les ressources sont prêtes :

La première commande va chercher tous les pods en cours sur tous les namespaces alors que la seconde va vérifier toutes les ressources sur le namespace Kubeflow (pods, deploy, services, replicat).
Quand les pods sont prêts, on peut voir un résultat similaire à celui-ci :

2.3.4. Kubleflow Pipeline UI
Maintenant que les ressources sont prêtes, on peut aller voir l’interface utilisateur de Kubeflow :
![]()
Cette commande utilise un port local pour afficher la sortie du pod :
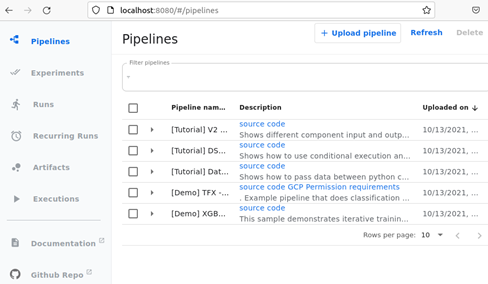
Figure 4: Kubeflow Pipeline UI
L’affichage du dashboard est composé de plusieurs sous-parties. La sous-partie Pipelines délivre la possibilité de visualiser les pipelines existants, soit ceux par default. La sous-partie Experiementspropose un moyen de regrouper plusieurs runs dans un même espace donné.
Pour utiliser les pipelines en local, en créer et déployer, il faut installer le sdk de Kubeflow pour les pipelines (kfp) :

Un pipeline Kubeflow est donc une description d’un workflow de machine learning, de tous les composants et de la manière dont ces derniers se comportent entre eux et sont visibles dans l’UI comme un DAG (directed acyclic graph).
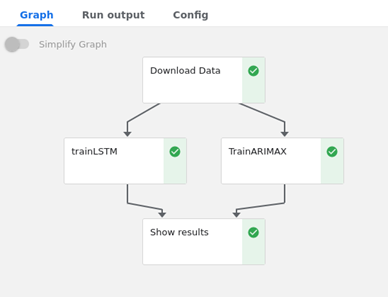
Figure 5.1. : Graphe de pipeline
Figure 5.1 : Graphe orienté acyclique, Crédit Simon PROVOST
Les étapes pour créer une pipeline sont les suivantes :
1/ Créer les composants :
o Code source ;
o Dockerfile ;
o Image Docker ;
o Publier l’image dans un registre (dockerhub par exemple).
2/ Créer les configuration yaml ( liées aux composants, images avec les entrées et sorties).
3/ Créer le fichier de description du pipeline :
o Fonction principale / pipeline ;
o Chargement des composants ;
o Liaisons / dépendances entre composants ;
o Déploiement / run.
Pour créer une image Docker :

Le docker_buildkit permet de monter dans le docker file un système de cache (ne pas oublier le ‘.’ à la fin de la commande).
Uploadez l’image dans le registre docker hub :

L’image est souvent nommée selon le format nomutilisateur/registre:tag (exemple tdunglas/cookiecutter:training_image). Mais tout dépend de comment a été créé le registre.
Le fichier yaml associé à l’image créée est similaire à :

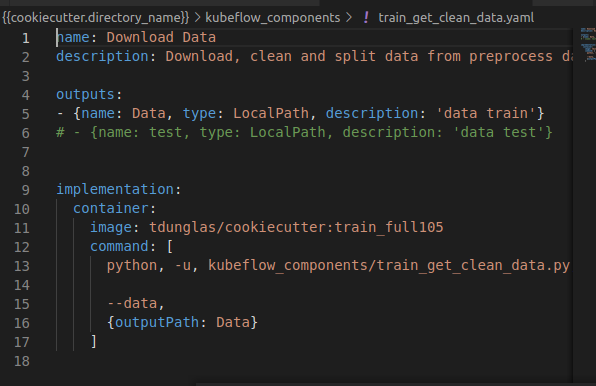
Figure 6 : Exemple de fichier yaml de configuration composant
Le fichier contient le nom du composant, sa description et les inputs / outputs, puis, dans son implémentation, l’image attendue et les commandes à appliquer sur l’image.
Le fichier de pipeline ressemble à une architecture :
-
Fonction pipeline avec le décorateur de pipeline ;
-
Chargement des composants yaml en tâches ;
-
Exécution des tâches ;
-
Déploiement / run.
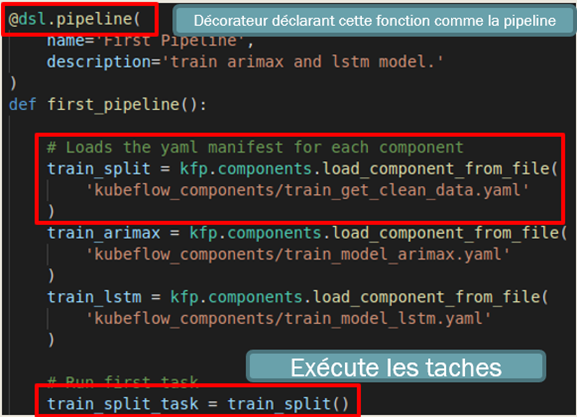
Figure 7 : Code du pipeline : fonction principale et chargement de composants
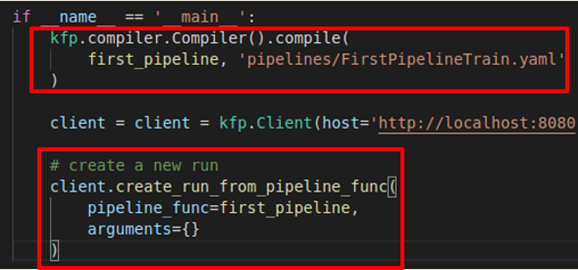
Figure 8 : Code du pipeline : compilation en pipeline yaml et création de runs
Maintenant, deux façons de poursuivre s’offrent à vous :
1/ Utiliser la pipeline yaml obtenue
o Importer / mettre à jour le nouveau pipeline sur la page pipeline UI ;
o Créer une nouvelle expérience / en utiliser une existante ;
o Créer un nouveau run.
2/ Utiliser le run créé par le code
o Le run créé de cette façon utilise le default experiment.
Sur l’interface utilisateur du pipeline au niveau du run, on voit le graphe et les logs de chaque composant. Cependant, si des erreurs ne sont pas assez renseignées, on peut débugger le pipeline en lui-même :

2.4. Memory usage
La création de clusters, containers et images Docker prend de la place. Voici comment visualiser et libérer de la mémoire utilisée sur Linux :

Cette commande permet d’obtenir une vision générale du système, mais pour avoir plus de précision sur les ressources Docker, voici comment faire :

Ensuite, listez les images, les containers et toutes les ressources de Docker. Sur Linux, le dossier /var/lib/docker/overlay2/ devient vite volumineux avec chaque nouvelle image.
Pour libérer de l’espace :

Déployer Kubeflow sur un cluster AKS
Après avoir testé Kubeflow en local, on peut maintenant le déployer sur un cluster Kubernetes managé par un cloud provider. Avec Azure, il est nécessaire de créer certaines ressources :
-
Un ressource group (après s’être authentifié) :

-
Un cluster (puis créez les crédentials pour l’utilisateur local) :
Pour déployer Kubeflow sur Azure avec la configuration générale (pipeline, notebook, katib), il faut utiliser le binaire kfctl (uniquement disponible pour Linux et Mac pour la dernière version actuelle : 1.2.0) :
-
Téléchargez le binaire : Releases · kubeflow/kfctl ;
-
Puis vous devez extraire le binaire ;
-
Ensuite, exécutez les exports (optionnel) du binaire dans le $PATH, nom du dossier, nom du déploiement, chemin au dossier, l’URL de la configuration ;
-
Enfin, dans le dossier choisi, appliquez le binaire avec la configuration renseignée dans l’URL.

Pour vérifier que les ressources ont bien été déployées :

Déployer Kubeflow Pipelines
L’environnement global de Kubeflow a été déployé dans la partie précédente mais on peut personnaliser davantage un déploiement juste pour la partie pipeline. Pour cela, il est nécessaire de créer d’autres ressources dans Azure :
- ML workspace ;
- Registre de conteneurs ;
- Persistant Volume Claim ;
- Service principal.
Dans le portail Azure pour ML workspace :
- Sélectionnez le groupe de ressource créé dans la partie précédente ;
- Choisissez l’option “ajouter une nouvelle ressource” ;
- Sélectionnez Machine Learning Studio Workspace.
Dans le portail, pour le registre de conteneurs :
- Créez une nouvelle ressource dans le groupe de ressources ;
- Sélectionnez Container Registry ;
- Autorisez le registre de conteneurs à donner son accès au cluster :
Pour le persistent volume claim (qui est utilisé pour provisionner automatiquement le stockage en fonction d’une classe de stockage), on peut créer le fichier yaml (pvc.yaml) avec les spécifications suivantes :

Puis appliquez ce pvc :
Uploadez un pipeline et lister les pipelines :

Référence : https://www.kubeflow.org/docs/distributions/azure/azureendtoend/
La preuve par l’exemple avec le pipeline FirstPipelineTrain.yaml généré précédemment : on peut le déployer avec kfp puis lancer des runs dans une même expérience.
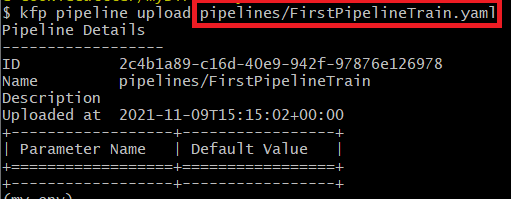
Une fois uploadé, le pipeline est visible dans l’interface de Kubeflow.
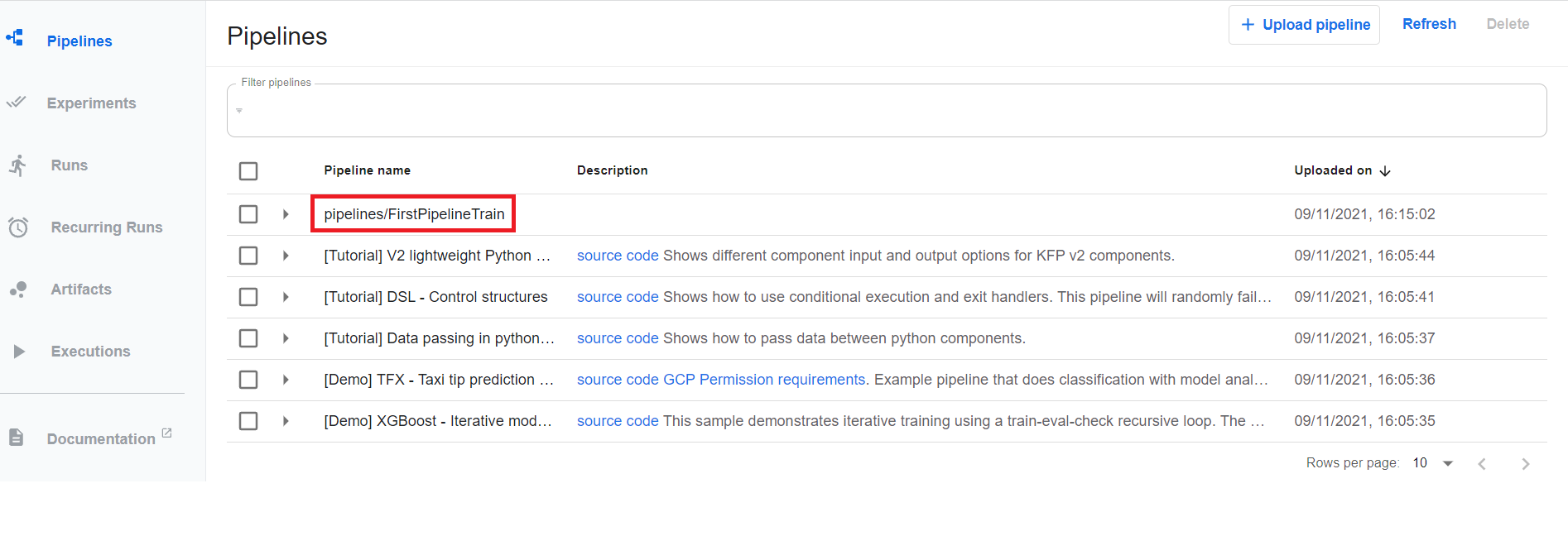
À partir de ce pipeline, on peut lancer des runs dans une même expérimentation, experiment. Example ci-dessous :
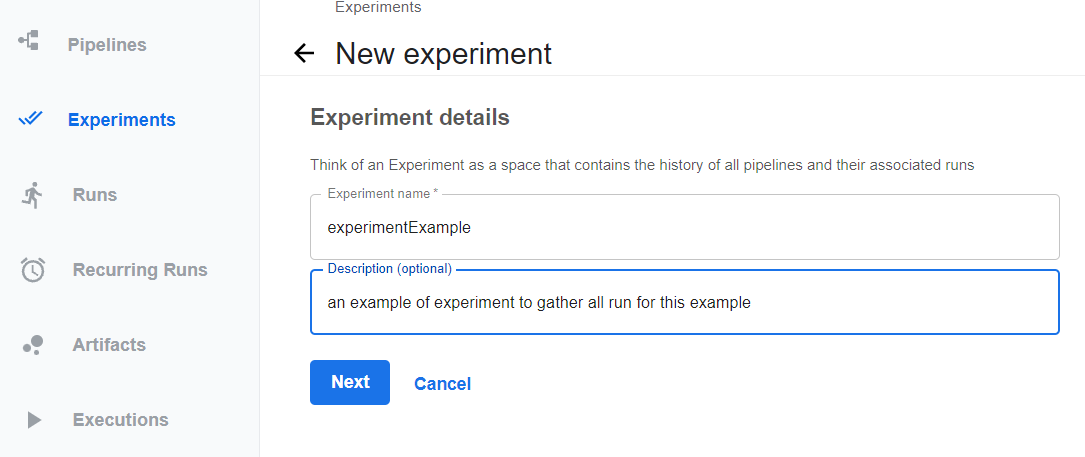
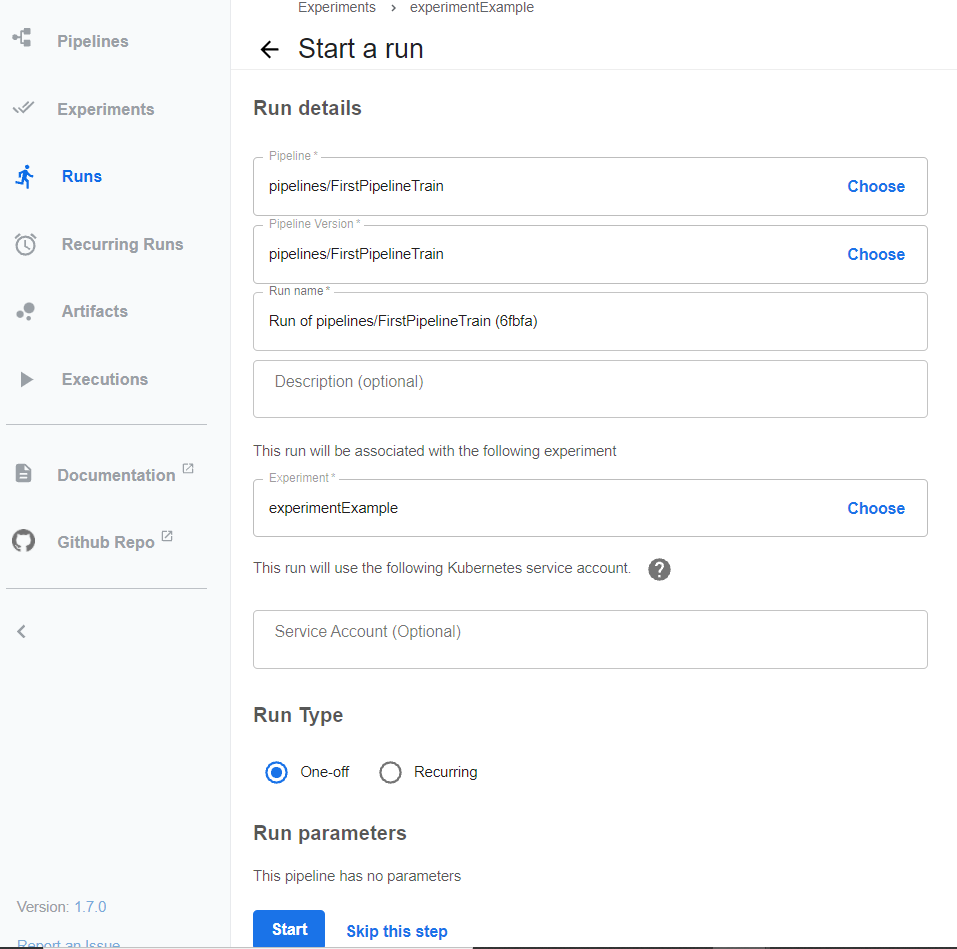
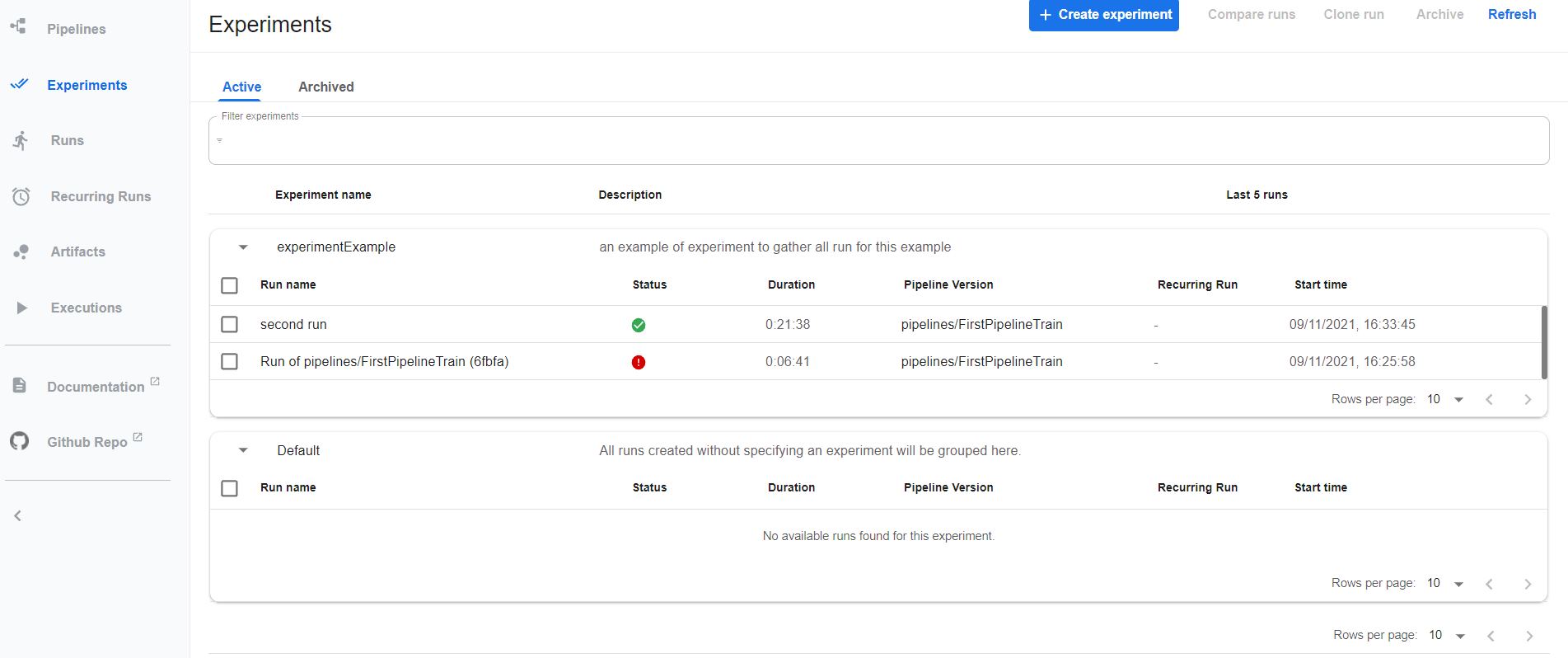
Dans l’expérience experimentExample, on voit bien les deux runs créés ainsi que leurs statuts :
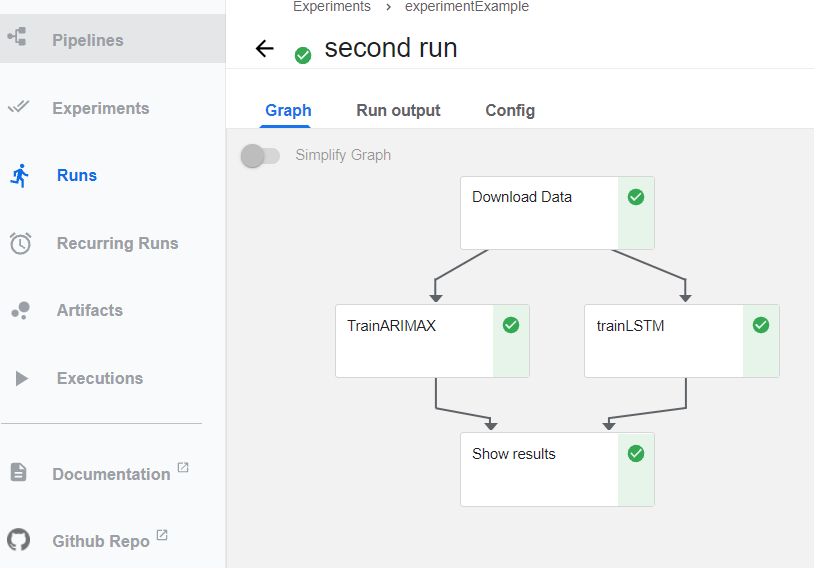
Dans le graphe orienté acyclique ci-dessous, voici le résultat final attendu correspondant au pipeline FirstPipelineTrain que nous avons uploadé :
Conclusion
Kubeflow est une solution adaptée à la fois pour tester en local et pour déployer sur un cloud provider un processus automatique d’entraînement de machine learning.
La force de Kubeflow repose sur son versioning, sur le regroupement des expérimentations et sur l’orchestration de ses pipelines facilement modifiés selon les hypothèses de travail du data scientist. Autre atout majeur : sa forte compatibilité avec Kubernetes lui permet d’exécuter en arrière-plan la gestion des ressources du cluster, permettant aux data scientists de se concentrer principalement sur leurs algorithmes.
Il existe toutefois d’autre solutions pour orchestrer l’entraînement de machine learning comme Airflow, Mlflow… qui peuvent être utilisées soit en substitution avec Kubeflow pour certains, soit en collaboration pour d’autres. En revanche, Kubeflow est un outil polyvalent de choix, avec des fonctionnalités intéressantes pour un grand nombre de projets, et sa facilité de déploiement sur Kubernetes le rend accessible rapidement pour les équipes data scientists.