
La mise en production de solutions data science est une phase délicate en raison des risques potentiellement élevés et de la complexité technique de sa mise en oeuvre. Dans cet article, nous vous présenterons les outils et les méthodes qui, de notre expérience, permettent de faciliter la mise en production de solutions explorées à l’occasion de PoC. Loin d’effectuer un tour d’horizon exhaustif de l’existant, l’idée est d’émettre quelques suggestions afin de faciliter le passage en production de vos projets data.
Par Johan JUBLANC, Head of Data de LittleBigCode
Lors d’une mise en production d’une solution data science, la première difficulté provient souvent du fait que nous ne savons pas à l’avance si la solution aura la même performance en conditions réelles que lors du PoC ou en comparaison à la version précédente, ni même si elle apportera effectivement de la valeur aux utilisateurs·rices.
Dans certains cas, la mise en production peut même aboutir à des actions aux conséquences catastrophiques ⏤ service inutile, prédiction erratique, etc. ⏤, d’autant plus difficiles à prévenir que les solutions mobilisent parfois des modèles « boîtes noires » dont l’interprétation est peu aisée.
Autres défis liés au passage en production : celui des expertises techniques variées mobilisées ⏤ gestion de bases de données, orchestration de tâches, service de modèles, gestion de pipeline, gestion des ressources, modification de l’infrastructure logicielle, etc. Et ce ne sont pas les seules compétences nécessaires ! Cette étape implique également des connaissances business et métier sans lesquelles nous ne pourrions apporter la valeur attendue aux clients finaux. Face aux multiples points de complexité rencontrés, il s’avère donc utile de connaître les outils et méthodes qui peuvent vous aider à simplifier la mise en production de vos solutions data science.
« Value first »
Chez LittleBigCode, nous plaçons la valeur que nous apportons aux client·e·s / utilisateur·rice·s au coeur de notre réflexion. Pourquoi ? Parce que cela nous permet :
• De donner une direction à nos projets
• De faciliter leur réalisation
• D’adopter le point de vue de nos client·e·s / utilisateur·rice·s
• Et de chercher à avoir un impact durable à travers des projets qui ont du sens
C’est pourquoi nous tentons de valider systématiquement que nous sommes bien en train de créer des solutions ayant un intérêt et porteuses d’un service utile avant de passer en production. À la clé : la capacité à renforcer la confiance de l’équipe et des décideurs dans le projet en légitimant le temps et les moyens investis pour développer et déployer la solution envisagée.
Valider la valeur finale avec un prototype
Une des méthodes que nous avons adoptée est d’appliquer les Sprints de Jack KNAPP (de Google Ventures) à nos problématiques orientées data. Cela nous permet de trouver des idées et de valider leur valeur ajoutée en 1 semaine. Quelle que soit l’issue, nous apprenons et nous économisons le développement et le déploiement de solutions n’apportant pas de valeur.
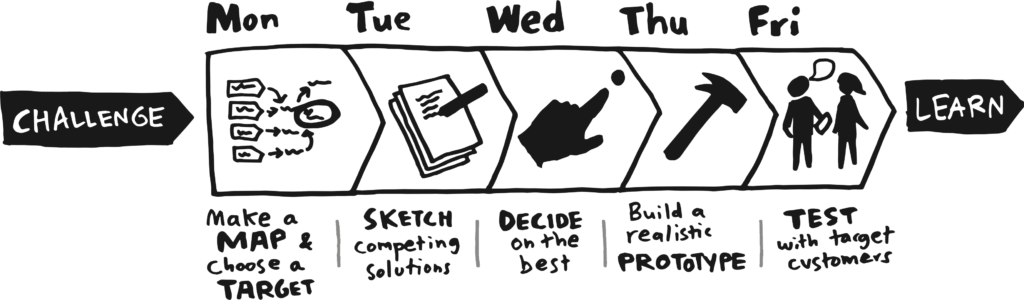
Se mettre dans la peau de l’utilisateur·rice
Pour valider que le service rendu correspond bien à un besoin, la partie qui nous semble essentielle est de pouvoir valider avec des utilisateur·rice·s que nous sommes bien en train de résoudre un problème, de réduire une difficulté, d’améliorer l’expérience du client, etc. L’idéal est de pouvoir tester la solution dans des conditions les plus réelles possibles, comme à la fin d’un Design Sprint.
Lorsque cela n’est pas possible, nous proposons de définir un persona, c’est-à-dire une personne fictive dotée d’attributs (âge, habitudes, loisirs, ect.) représentant un groupe cible et permettant de centrer la conception de la solution sur les utilisateur·rice·s. Il existe de nombreux templates et méthodes pour créer un persona, tel que le guide de création proposé par Xtensio.
Assurer une performance durable
Réentraîner et monitorer ses modèles
Dans de nombreux cas, des modèles entraînés sur des données anciennes vont perdre en performance voir devenir obsolètes. Par exemple : des modèles de prédiction de consommation d’énergie vont dépendre d’un contexte qui peut changer rapidement en fonction de l’évolution des habitudes, des avancés technologiques, etc.
Pour s’assurer de ne pas avoir de décalage entre les données d’entraînement et les données utilisées lors de prédiction, il peut être intéressant de prévoir un réentraînement régulier des modèles. Pour ce faire, il est possible d’utiliser un orchestrateur comme Airflow.

Toutefois, le réentraînement ne suffit pas à lui seul. Il nous semble en effet primordial de pouvoir suivre l’évolution des performances au cours de réentraînement successifs. Comment ? Grâce à des outils tels que le MLFlow. Parmi ses atouts : il permet d’assurer ce suivi, mais également de créer des logs avec des métriques de performances et d’enregistrer les modèles, les scalers, et tout autre artefact intégrant une pipeline de machine learning. Avec un minimum de configuration, MLFlow permettra d’enregistrer les versions des données utilisées (dates des plages de données, origines des données, etc.). 
Une interface permet ensuite de suivre l’évolution des métriques principales et de récupérer l’ensemble des éléments permettant de reproduire les expériences d’entraînement.
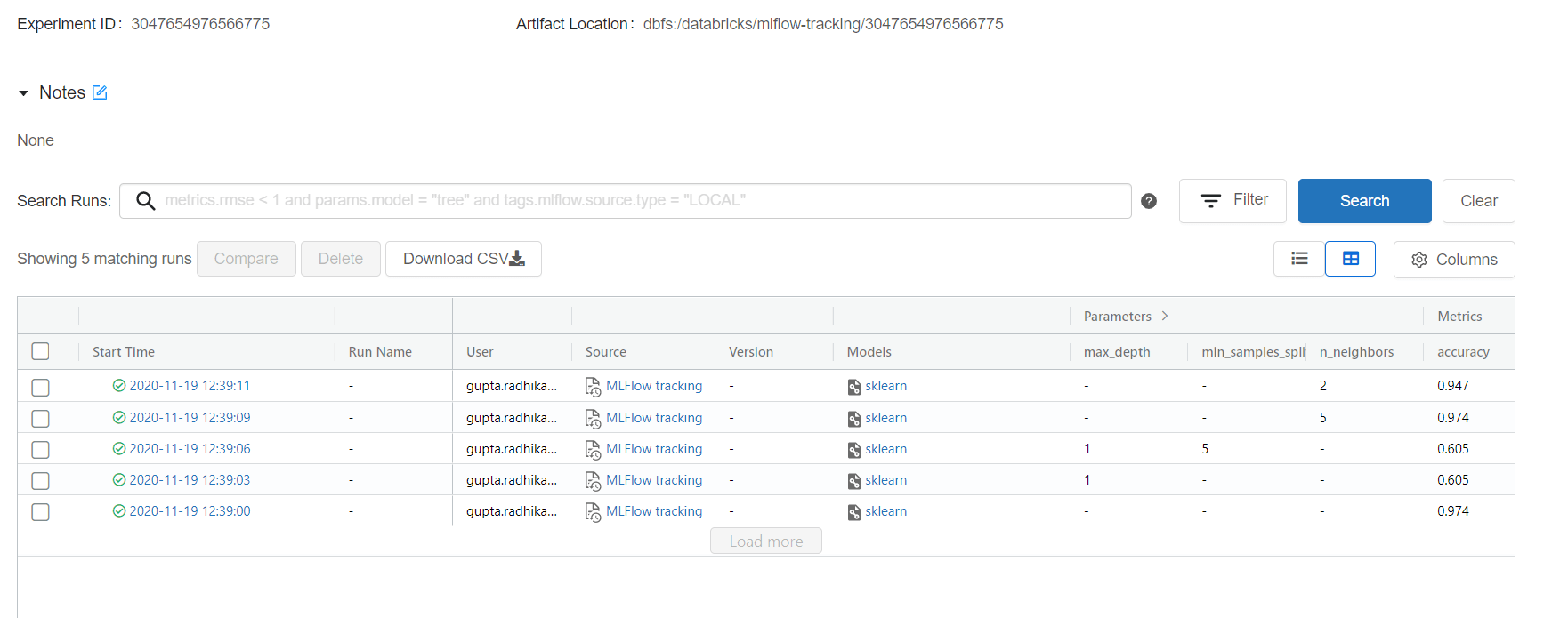
Exemple d’UI mlflow (source : MLFlow Tracking)
Contrôler ses données
Ensuite, il importe de renforcer le contrôle de ses données. Comment ? En s’assurant de la cohérence entre les données d’entraînement et les données de prédiction. À commencer par le fait que :
- Le schéma global (noms et types de colonnes) n’a pas été modifié, source d’erreur lors de l’exécution du code
- Il n’y a pas dérive des plages de données : les valeurs de prédiction se situent entre les bornes des valeurs d’entraînement, les statistiques globales des données sont comparables entre l’entraînement et la prédiction, etc.
De nombreux moyens peuvent être mis en oeuvre pour éviter ces problèmes. Nous avons notamment expérimenté et apprécié Tensorflow Data Validation (TFDV). Parmi ses avantages : il permet à la fois d’explorer les données au moment de la phase initiale de développement du produit, et de valider les données lors des mises à jour et du déploiement de nouvelles versions.
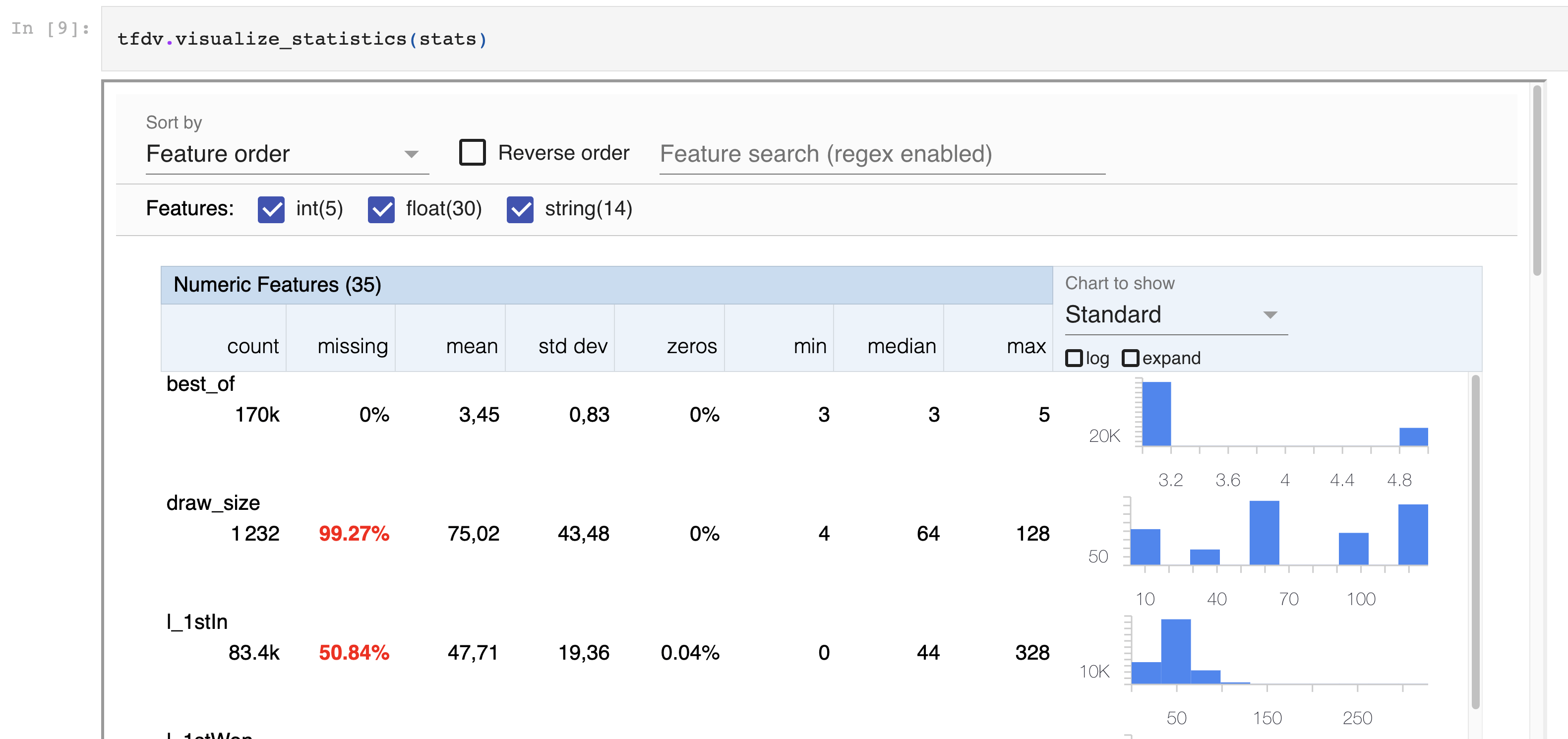
Exemple de la visualisation des données dans un notebook Jupyter (source : Johan JUBLANC)
Mesurer la valeur que l’on apporte
Chez LittleBigCode, nous pensons que l’industrialisation de solutions data science passe par la validation de la valeur apportée. La raison est simple : sans cela, les blocages seront nombreux et les risques élevés, engendrant des ralentissements du développement de l’entreprise et, dans certains cas, des prises de décision génératrices de pertes parfois non négligeables.
Pour fluidifier et sécuriser les mises en productions successives, il nous semble alors essentiel de mettre en place une politique de suivi de la valeur ajoutée de la solution et de ses différentes versions. De nombreuses techniques existent. Nous ne présentons ici que quelques outils et méthodes qui peuvent vous inspirer.
Les solutions proposées par les data scientist peuvent (et c’est souvent le cas) mobiliser un ou plusieurs modèles de machine learning. Mais le service final n’est bien souvent rendu que par l’utilisation de ces modèles, l’automatisation des tâches, l’accès aux résultats via une interface ou une application, etc. Aussi, la valeur apportée par la solution data science n’est pas vraiment mesurée par les métriques d’entraînement des modèles.
De notre point de vue, au moment de l’industrialisation de la solution, il est important d’observer des KPI qui représentent le mieux possible la valeur finale que l’on souhaite délivrer. Il est notamment crucial de se concentrer sur l’ajout de la solution par rapport à une situation initiale afin de ne pas tomber dans « l’illusion de la performance ».
C’est pourquoi, dans une majorité de situations, nous proposons d’analyser la valeur par une mesure de différence – nous recherchons alors la valeur incrémentale de la solution. Voici quelques exemples :
- Diminution du temps de réalisation d’une tâche
- Augmentation du taux de conversion, du chiffre d’affaire, de la marge
- Amélioration de la satisfaction client
- Réduction des pertes
- Etc.
Tester avant de déployer une nouvelle version
Avant de déployer complétement une nouvelle version d’une solution data science, il est toujours rassurant de valider que « tout se passe bien » : c’est-à-dire que les performances de la nouvelle version sont meilleures et qu’il n’y a pas d’effet indésirable lors de l’utilisation.
Si la solution est servie via une application distribuée, il est possible de commencer par déployer les nouvelles versions auprès d’un petit nombre d’utilisateur·rice·s. Objectif : valider l’amélioration continue de la valeur apportée par la solution et, le cas échéant, déterminer les correctifs à apporter à sa solution. On parle alors de déploiement canary.

L’utilisation d’une API gateway comme Istio est l’une des options pour effectuer ce type de déploiement ou d’autres stratégies sur un cluster K8S. Les utilisateur·rice·s sont envoyé·e·s vers l’une des versions de l’application avec une proportion définie par l’équipe.
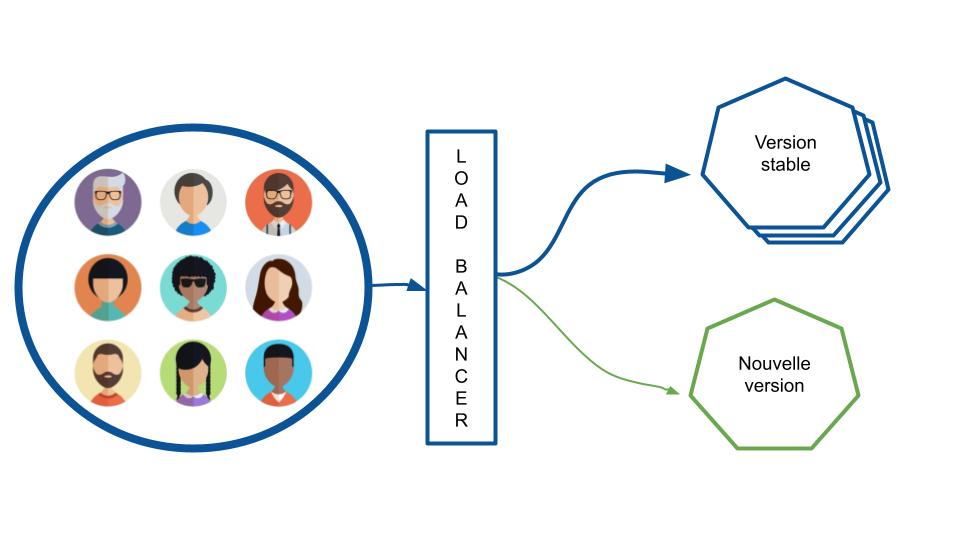
Source : Johan JUBLANC
Réaliser un A/B Test qui a du sens
Une méthode que nous recommandons, lorsque cela est possible, pour observer l’impact d’une solution auprès des utilisateur·rice·s (sur le taux de conversion, le CA ou la rétention notamment) est de réaliser un A/B test. Un déploiement canary, par exemple, donne l’occasion de récupérer les données qui seront analysées ensuite lors du test. Pour apporter de l’information utile, il nous semble important d’adopter une démarche statistique rigoureuse.
Tout d’abord, on va chercher à déterminer l’effet minimum que l’on veut détecter. De quoi s’agit-il ? C’est la valeur du gain minimal en dessous de laquelle la solution n’a pas d’intérêt. Résultat, l’effet minimum dépend fortement du contexte business et du besoin métier. On peut ainsi se dire qu’une solution n’est pas suffisamment intéressante si l’augmentation du taux de conversion est inférieure à 2 % .
Comme nous observons des échantillons, il y a toujours un risque que la conclusion du test soit erronée. Le risque de première espèce correspond au cas où l’on conclut que la solution apporte de la valeur alors que ce n’est pas le cas. En général, on utilise 5 % ou 1 %. À l’inverse, le risque de deuxième espèce représente la situation dans laquelle on conclut à tort que la solution n’apporte pas de valeur. En général, on fixe une limite à 20 % et le risque réel constaté est inférieur.
Une fois que l’effet minimal et les risques ont été établis, nous pouvons alors calculer les tailles des échantillons correspondants, en tenant compte de l’hétérogénéité des comportements au sein de chaque groupe. Plus les tailles des échantillons seront grandes, plus les distributions seront « resserrées» autour de la moyenne et plus les risques de première espèce (zone bleue) et de deuxième espèce (zone orange) seront réduits.
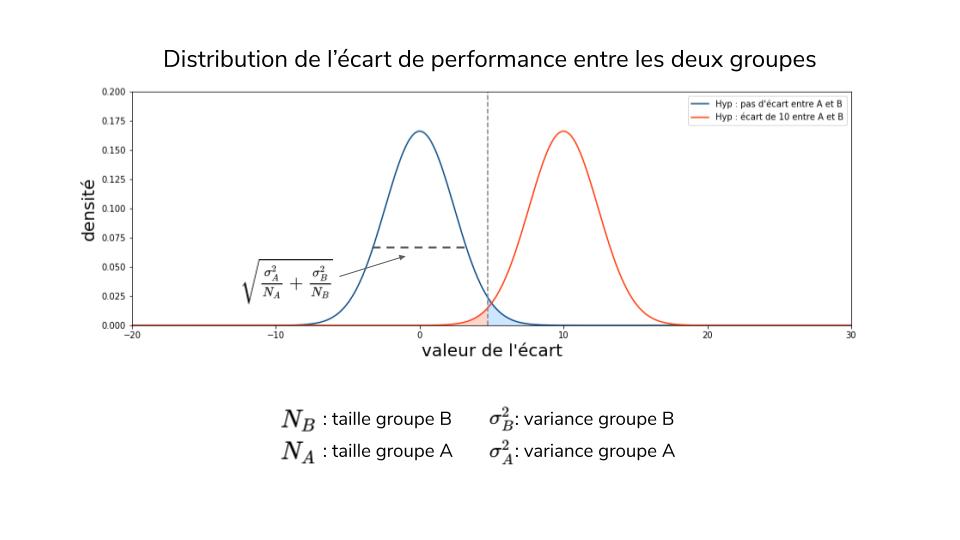
(Source : Johan JUBLANC)
Garder le contrôle
La nouveauté s’accompagne souvent d’inconnues et donc de risques de mener des actions dont les conséquences sont incertaines. Pour éviter les catastrophes et les répercutions dramatiques, nous proposons de maintenir un maximum de contrôle sur les actions réalisées par votre solution.
Les règles métier comme garde fou
Il existe souvent des règles métier préexistantes à la solution que l’on met en œuvre. Par conséquent, pour sécuriser la mise en production d’une nouvelle solution, il est possible de basculer automatiquement vers ces règles dès que l’on observe une dérive des performances, de la satisfaction client ou tout autre KPI pertinent pour l’entreprise.
Alerting
Ces actions de mise à l’arrêt de l’exécution de la dernière version d’un modèle ou d’un processus complet peuvent être complétées par un système d’alerting. Son rôle est de repérer des dépassement de seuil, par exemple pour des dépenses, et de transmettre directement un message sur le canal le plus adapté : email, Teams, Slack, etc.

Conclusion
La mise en production est une étape clé de la réalisation d’un produit data science. C’est lors de cette phase que l’on prend le plus de risques, mais également que l’on permet à la solution d’apporter de la valeur aux utilisateur·rice·s.
Nous vous avons présenté des méthodes et des outils pouvant être utilisés pour limiter les erreurs et contrôler la performance de la solution mise en production, mais également capables de récupérer de l’information sur la valeur globale apportée par le produit. Un apport de valeur que, chez LittleBigCode, nous mettons au cœur de nos réalisations, de l’idéation jusqu’au déploiement, car nous pensons qu’il s’agit d’un élément essentiel, qui donne du sens à nos projets.
En ce sens, le schéma ci-dessous synthétise la mise en œuvre de ce que nous avons présenté dans l’article.
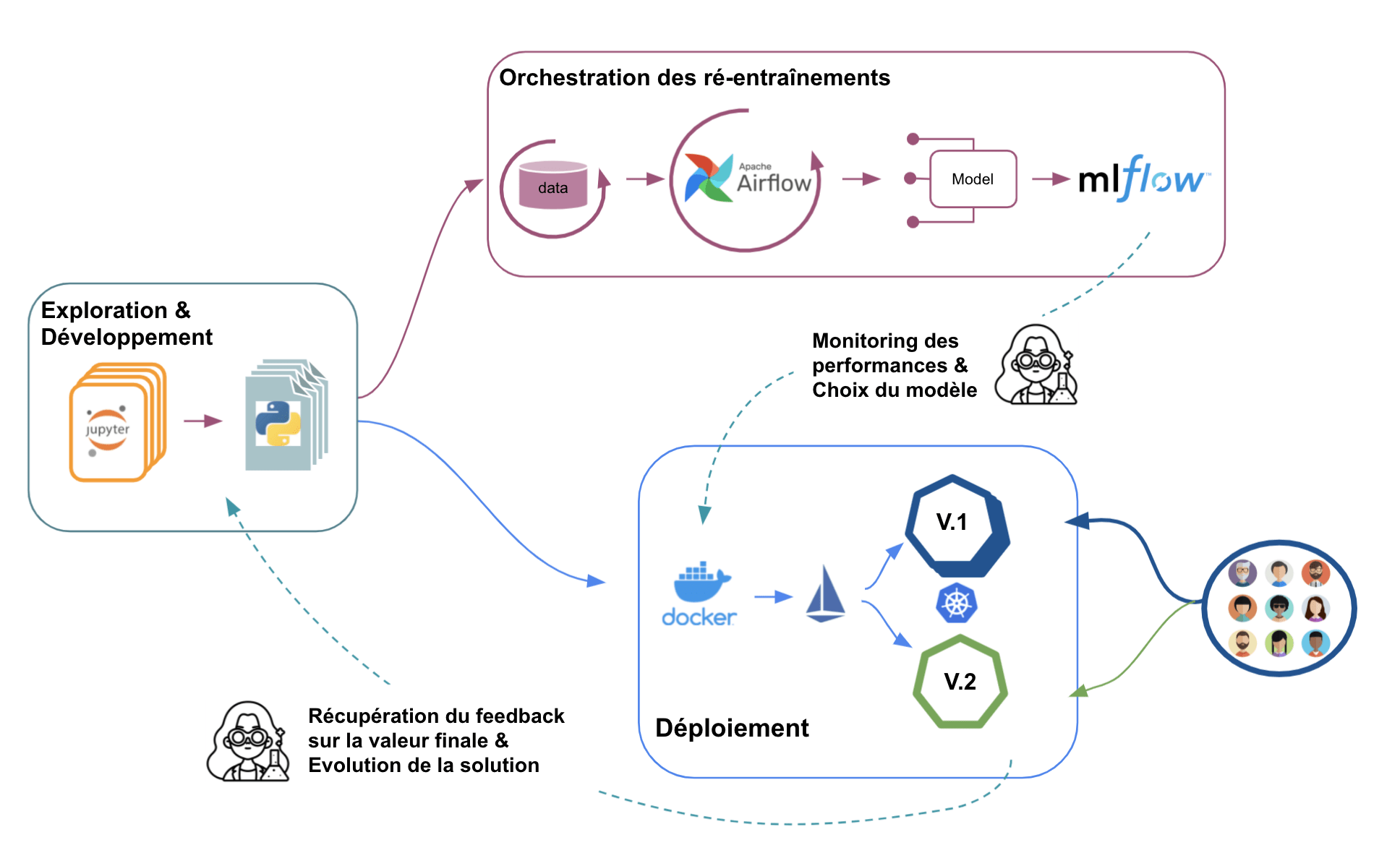
Exemple de workflow de mise en production d’un produit data science (Source : Johan JUBLANC)
Bien entendu, ce ne sont pas les seules solutions possibles et le schéma proposé n’est pas exhaustif. Dans un prochain article, nous apporterons de nombreux compléments pour réaliser un pipeline de mise en production plus avancé et plus automatisé.
Recent Comments