Is the NVIDIA GenAI Certification worth It? Our honest review
Margot Fournier and myself (Matthieu De Cibeins) are data scientists consultants at LittleBigCode. We successfully went through NVIDIA GenAI learning path and Certification in October 2024. This article aims at providing an honest feedback about its strengths and weaknesses, an overview of the learning path, and as much detail as possible on how to prepare it best.
Why choose NVIDIA GenAI Certification ?
Due to the various types of data and their specificities, the scope of data science is so large that it is rare to find any data scientist that masters various domains of expertise within it (time series, computer vision, tabular data, natural language processing, and so on). Yet, given the extremely fast evolution of the AI ecosystem – as the current GenAI buzz outlines – it remains relevant for an AI consultant to demonstrate a minimal level in all fields, so as to be able to understand the basic concepts of each of them. That’s the core concept of the “T-shape” competency matrix dear to LittleBigCode.
 Illustration of the T-Shape
Illustration of the T-Shape
Given the fast evolution of the GenAI technologies, finding the right learning path to quickly upgrade your skills in GenAI was a strategic task for LittleBigCode, and led to the choice of two consultants to benchmark NVIDIA’s GenAI certification : a senior data science consultant, with strong expertise in time series and tabular data but less knowledge in GenAI ; and a more junior consultant, with background in time series and satellite data but also some experience with older NLP models such as BERT.
Among GenAI certifications, choosing NVIDIA’s one was quite straightforward. As a matter of fact, a handful of companies risked themselves to build learning paths and certifications around this rapidly changing domain – the big boys, Google and Microsoft, might be waiting for the GenAI wave to settle. NVIDIA didn’t. This appeared as a great opportunity to benchmark the technologies of this giant of the AI hardware – not to mention that they’re also growing their software offer, which made this formation even more interesting.
What does NVIDIA GenAI Certification consist of?
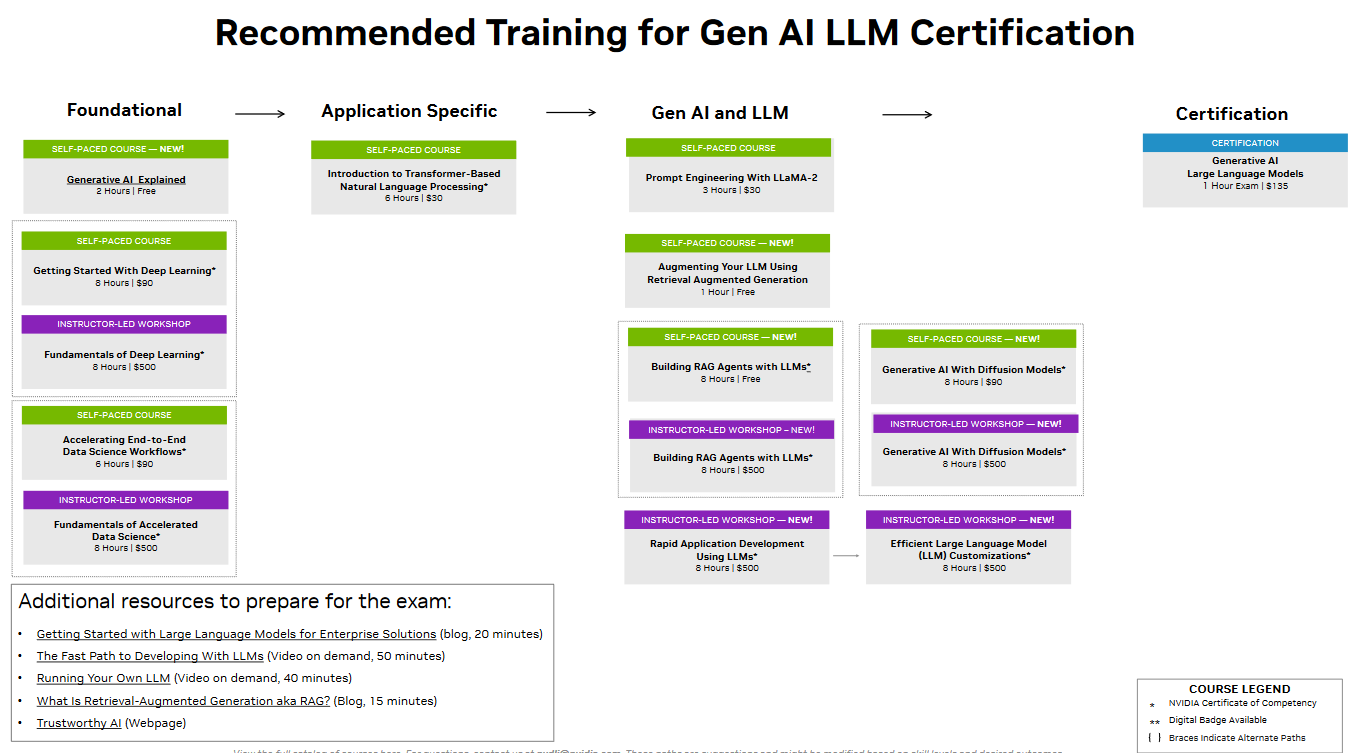
It consists of :
-
a learning path including several modules grouped in 3 themes : Foundational, Application specific, GenAI and LLM.
-
an exam delivering the certification
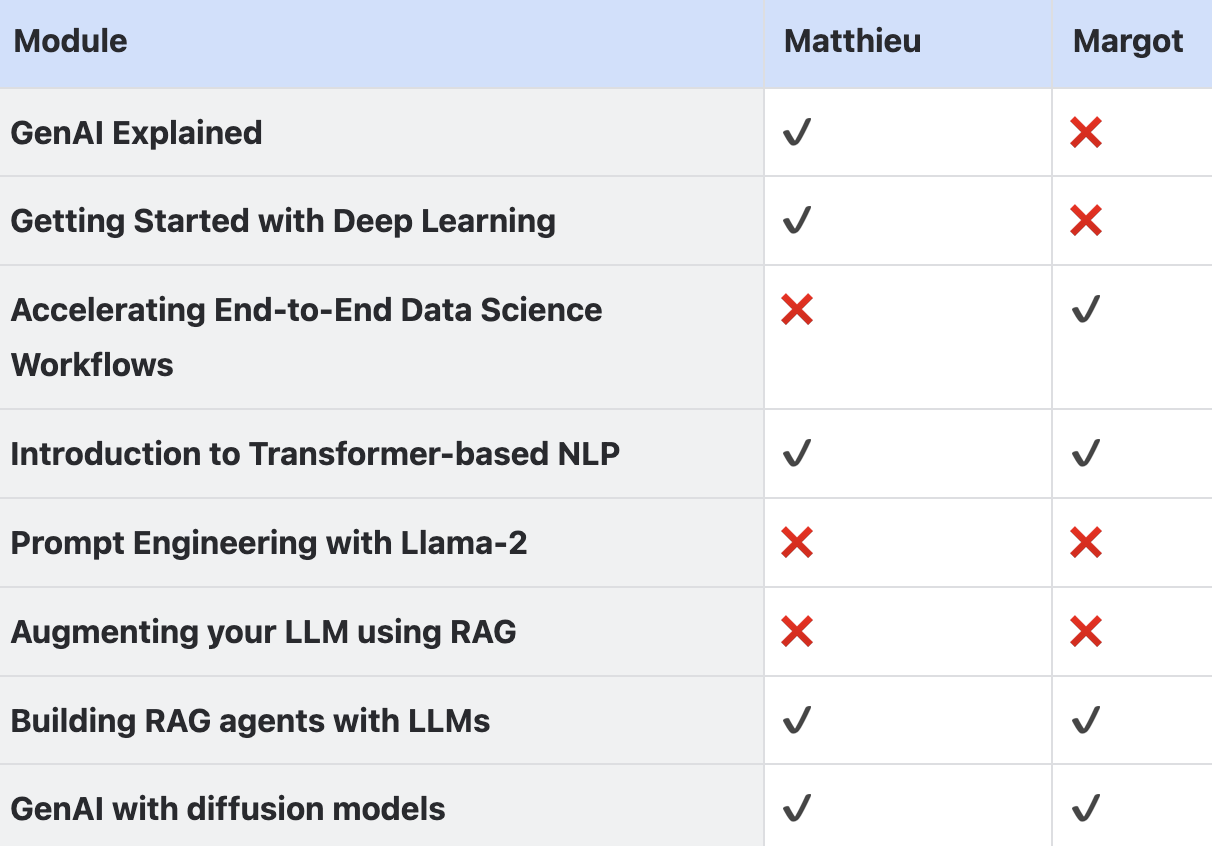
As we understood later, those modules are not supposed to be considered in an exhaustive way, but rather cherry-picked depending on your skills and experience in each domain. We focused on the green modules (self-paced) and chose to split our learning paths the following way :
In the end, the exam consists of a 50-question MCQ to be completed in an hour.
In the following section, we will give an overview of each module we went through.
What we learned
1. GenAI explained
This foundational module provides a global overview of what the buzz word “GenAI” covers. It aims at defining the basic concepts of GenAI for beginners, as well as giving examples of real life applications – Language, Images, and so on. But it also introduces more elaborated concepts : how we aim to capture the data distribution to generate samples based on conditions ; strategies to fine tune generation models based on human feedback, composition between text and images… Finally, a wrapup of the challenges and opportunities of GenAI provides an opportunity to take a step back and list all the considerations that need to be taken into account when further developing a GenAI application.
Feedback on the Course
-
Pros: It really is a good appetizer for apprehending all the aspects of GenAI, not just the opportunities, but also the many challenges that come along. The course teacher is very pedagogic.
-
Cons: You won’t take away much from this module, since it’s really an introduction and does not go into details. The quiz that rythms the module is ill-structured (for instance in case of wrong answer, one cannot see the reason why)
This module is thus a very helpful introduction for beginners, and can easily be skipped for people who already have GenAI notions.
2. Getting Started with Deep Learning
Here, we start going into details. This 90$, 8-hour course is a great opportunity to discover Deep Learning “the hard way”, i.e by putting hands in code. But it’s also a great refresher for people who already are familiar with deep learning, because it is very exhaustive and covers the main domains of deep learning :
-
The “hello, world” of Deep Learning : MNIST
-
The theory behind neural nets : gradients, backpropagation, optimizers, and so on
-
Convolutions main concepts – pooling, dropout, batch norm…
-
Data augmentation techniques and deployment considerations (when real life data is different than training data)
-
Pre-trained models and fine-tuning
-
NLP and transformers
For each topic, a 5-10 min lesson precedes a PyTorch implementation with pre-filled notebooks.
Feedback on the Course
-
Pros: Having previous experience with Deep Learning, I still found it useful as a reminder and very well structured, from simple to more complex subjects. I also learned a few techniques I didn’t know about. The notebooks are very well explained, with explanations between code cells. Finally, NVIDIA instances make it possible to train big models easily.
-
Cons: The notebooks are exhaustive and could be a bit less guided to incentize learners to grasp concepts by themselves. The length of the code doesn’t encourage to review and understand every line. Thus, it is tempting to quickly execute all cells which, after several lessons, results in less memorization of the concepts. Also, the course content could be longer and clearer.
To sum up, this module is a quite general detailed introduction to deep learning, and its main interest in my opinion resides in the global structure of the course, and the content of the NVIDIA-powered notebooks. Yet, you could easily find free theoretical resources on this subject.
3. Accelerating End-to-End Data Science Workflows
This module introduces NVIDIA RAPIDS, a suite of software designed to revolutionize data science workflows using GPU acceleration, boasting performance that is up to 10 times faster than conventional CPU methods.
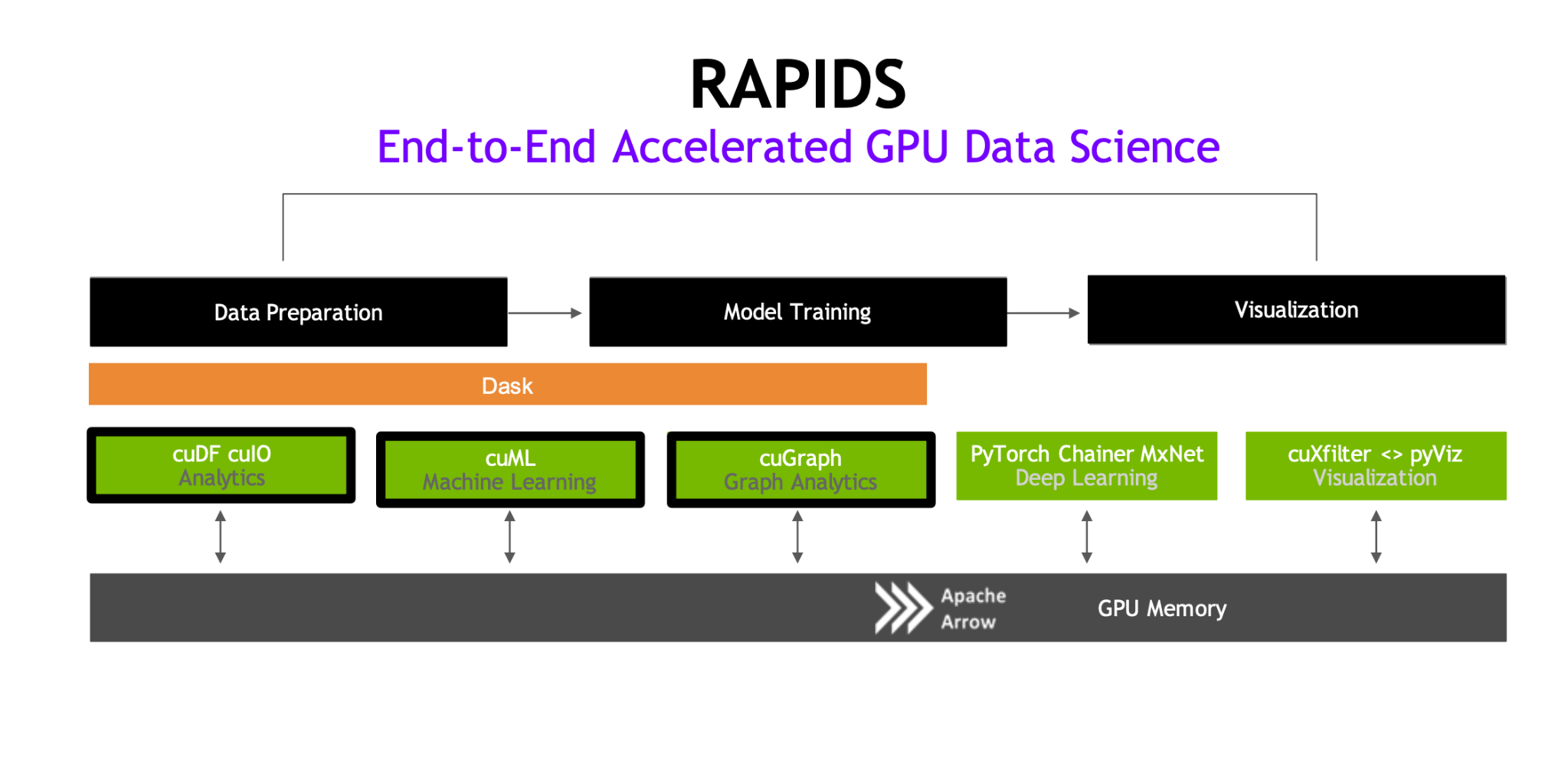
RAPIDS – End-to-end accelerated GPU Data Science
One of the appealing features of RAPIDS is its compatibility with well-known Python libraries. RAPIDS provides a GPU-accelerated equivalent for popular packages, allowing data scientists to migrate their workflows with minimal adjustments to syntax. Here’s a breakdown of some mappings:
-
Pandas vs. cuDF (RAPIDS): Both provide DataFrames for data manipulation, but cuDF accelerates operations using NVIDIA GPUs.
-
Scikit-learn vs. cuML (RAPIDS): Scikit-learn provides machine learning algorithms on CPU, whereas cuML accelerates these algorithms on GPUs.
-
Bokeh vs. cuXfilter (RAPIDS): cuXfilter offers real-time, interactive data exploration on GPUs, making it a suitable replacement for traditional visualization tools like Bokeh for GPU-based data.
The real strength of RAPIDS lies in its GPU acceleration and integration with Apache Arrow. Unlike traditional data science libraries designed for CPU processing, RAPIDS harnesses the parallel computing power of GPUs. This acceleration yields significant performance improvements—often 10x faster than CPU-only solutions like Pandas.
Another advantage is RAPIDS’ use of Apache Arrow, a memory format that minimizes data movement across storage layers, streamlining the data processing pipeline and reducing latency. With Arrow, data operations are more efficient, as it optimizes in-memory storage and aligns with GPU needs, enabling smoother processing.
Pros:
-
The training was concise, with courses spanning a few minutes each, allowing a focused approach without unnecessary information.
-
Step-by-step exercises were particularly effective, as they consistently showcased performance comparisons between RAPIDS and traditional libraries, with RAPIDS proving to be about 10x faster than Pandas in most cases.
-
A key benefit was the minimal syntax difference between classical libraries and RAPIDS—transitioning was straightforward, which reduces the learning curve for new users.
Cons:
-
One downside I noted was that RAPIDS documentation appears somewhat limited, which could make troubleshooting challenging.
4. Introduction to Transformer-based NLP
This course provides an introduction to transformer-based large language models (LLMs) and their applications in NLP tasks like text classification, named-entity recognition (NER), author attribution, and question answering.
Participants learn how to use pre-trained LLMs for applications such as chatbots and virtual assistants.
The course focuses heavily on configuration, using tools like OmegaConf, PyTorch Lightning, and NVIDIA’s NeMo. Instead of coding models from scratch, learners adjust configuration files to set up data paths, model parameters, and hardware specifics for GPU acceleration. This modular approach simplifies deployment and keeps workflows organized, but it may feel less hands-on, especially for those new to configuration-heavy setups.
Pros:
-
The course offers pre-configured example notebooks that are easy to implement, along with a helpful overview of PyTorch Lightning’s Trainer, covering essential actions like fitting, evaluation, and prediction.
Cons:
-
The course content is minimal, with very brief lectures and few practical exercises, limiting both theoretical and technical depth.
-
The overly simplified tasks and pre-processed configurations make it challenging to appreciate the complexities of real-world NLP.
5. Building RAG agents with LLMs
Probably the module we were expecting the most from, given that we both were familiar with the main concepts of LLMs, but none of us had manipulated nor implemented RAGs, which constitutes a very useful technique when it comes to translate the power of LLMs into real business applications.
The module was indeed very rich (and time consuming : we both spent way more than the indicated 8 hours, probably around 15). It covers the following topics :
-
Overview of LLM services, including NVIDIA’s ones
-
Langchain main principles (runnables, prompts, parsers)
-
Running state chains
-
Documents and chunking strategies
-
Embeddings and queries
-
Vector stores (from naive “always on” strategies to more complex ones with branching logic)
-
Evaluation (LLM as a judge, RAGAS)
Feedback on the Course
-
Pros: The course’s notebooks are very technical and allow to grasp some key concepts of RAGs. Real-life implementation considerations are covered (including evaluation)
-
Cons: The theoretical content (video+slides) is still quite sparse, some essential concepts are not given the time they deserve and it feels like the structure of the course is not easy to follow. The final notebook assessment is not trivial at all and requires to dig deep into the python code (including the understanding of how services interact with each other) and debugging is not easy. This complexity could clearly be avoided since it doesn’t add value to the RAG course.
6. GenAI with diffusion models
This course introduces learners to generative AI’s applications across industries, with a specific focus on denoising diffusion models for text-to-image generation. Participants gain hands-on experience building and optimizing U-Net architectures, applying diffusion processes to improve image quality, and using Contrastive Language–Image Pretraining (CLIP) for text-based image generation.
Feedback on the Course
-
Pros: The course’s notebooks are well-structured, introducing key PyTorch functions and parameters relevant to diffusion models, such as adding temporal dimensions and context embeddings. It offers insights into advanced optimization concepts, like classifier-free diffusion guidance, and provides some deeper technical exploration.
-
Cons: The NVIDIA platform’s slow VM launch time detracts from the learning experience, as does the low audio quality of lectures. The course content itself is limited in depth, often covering basic concepts (e.g., U-Net, GANs, convolutions) without challenging learners to think critically. While the notebooks are detailed, they allow for either a quick, surface-level run-through or an extensive deep dive, with limited encouragement for reflective learning.
Exam content
The main thing to keep in mind while preparing for the exam is that it is not purely focusing on the modules presented above, it rather evaluates a global knowledge of the GenAI field. A solid understanding of GenAI is required, from the main concepts of ML and DL, to more specific notions of NLP including RAGs. It also adresses NVIDIA-specific libraries and compute resources.
Additional topics that aren’t part of the learning path include for instance A/B testing or Ethical AI considerations.
Content-wise, the exam consists of 50 multiple choice questions to be completed in 1 hour :
-
45 questions ask for 1 answer out of 4 options
-
5 questions ask for 2 answers out of 5 options
To give you an idea of the weights of each section, I had approximately :
-
15 questions on general ML/DL topics (activation functions, transfer learning, layer normalization, vanishing gradients, dimensionality reduction, ML libraries, …)
-
15 questions on NLP concepts (motivation behind transformers, attention mechanism, few-shot learning, prompt engineering, sentiment analysis, NLP libraries, …)
-
5 questions on RAGs (chunking, langchain, vectorstores, document retrieval)
-
5 questions on NVIDIA compute (Triton inference server, NeMo, TensorRT vs ONNX, optimize CPU/GPU througput, …)
-
4 questions on A/B Testing (theory vs practice)
-
3 questions on Ethical AI (especially on the Content Authenticity Initiative)
-
1 question on Diffusion
Which, added to those I forgot, should sum up to 50 ![]()
Learnings from the NVIDIA GenAI LLMs certification, and additional thoughts
Overall, the modules are quite dense and definitely help you apprehend specific GenAI notions, even more so than you are a beginner in the field. Here are some extra thoughts that’ll hopefully help you decide whether to delve in this certification:
-
With this course, you’ll learn a lot on GenAI but it won’t be enough to complete the certification. Indeed, a global comprehension of the field is very beneficial to pass the exam. For instance, no module tackles A/B Testing or Ethical AI which are required for the exam. What’s more, some important topics of GenAI are not – yet – part of the learning path nor the exam, such as LLM-Ops.
-
The learning path include great modules but sometimes lacks a common thread. It has been built organically, modules have been added to NVIDIA’s Deep Learning Institute one at a time, and the certification came only after by regrouping some of those. As a result, it is sometimes not easy to see clear links between modules and beginners might feel quite lost at some times: which notions are essential? Which are nice-to-have?
-
Modules content quality is variable. Some of them truly have earned our consideration (kudos to “Building RAG agents with LLMs” and “GenAI with Diffusion Models”) while some felt a bit more empty in our opinion (“GenAI explained” or “Introduction to transformer-based NLP”). Some are very theoric (Diffusion) while other are super specific (RAGs). Besides, extra consistency between modules – speakers, recording quality (surprisingly), time spent on notebooks – would be greatly appreciated.
We hope that this article was insightful. Don’t hesitate to reach out to us if you have any questions or remarks and we’ll be happy to help!
Recent Comments