
You have been working on a proof-of-concept using a Machine Learning pipeline that is being scaled up ? Congratulations, you have done a wonderful job: only 13% of the data science project actually make it to production!
Now you are being asked a lot of questions such as: how do you intend to put the model in production? How is your team ensuring that the model is still sufficiently accurate? How can operations explain the model predictions? What about compliance and model governance?
Machine Learning Operations (also called MLOps) is the answer to all of that. Let us attempt to comprehend how these so-called MLOps can assist us in successfully running AI.
By Jamila REJEB, Data Scientist at LittleBigCode
Is MLops a new trend ?
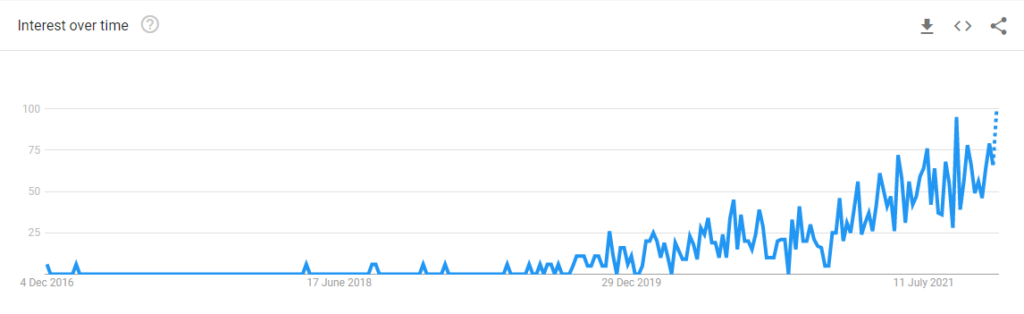
You have probably heard of DevOps, which is a movement that aims to reconcile two professions: the software developer (dev) on the one hand, and the systems and architecture administrator (ops) on the other hand. However, MLOps is a much newer concept. As a matter of fact, if you search for MLOps on Google trends, you will see that it is a relatively new discipline.
As more and more businesses are turning to ML models to get insights, organizations are attempting to integrate ML systems into their products and platforms.
Therefore, the process of operating ML needs to be as buttoned-down as the job of running IT systems.
What is MLOps ?
MLOps stands for Machine Learning Operations. Just like DevOps, MLOps is born to optimize, accelerate and secure the production lifecycle.
MLOps is not a job profile but a methodology / a set of best practicesthat aims to deploy and maintain machine learning models in production reliably and efficiently. How? By working through the lens of organizational interest with clear direction and measurable benchmarks.
Similar to how DevOps shortens production life cycles by improving products with each iteration, MLOps drives insights you can trust and act on sooner.
MLOps, DevOps, DataOps : what’s the difference ?
Both DevOps and MLOps aim to place a piece of software in a repeatable and fault-tolerant workflow, while MLOps adds a machine learning component to that software.
However, MLOps ultimately has a few more nuances for each component of the workflow that differ from traditional DevOps such as data labelling, data transformation, feature engineering, and algorithm selection process.
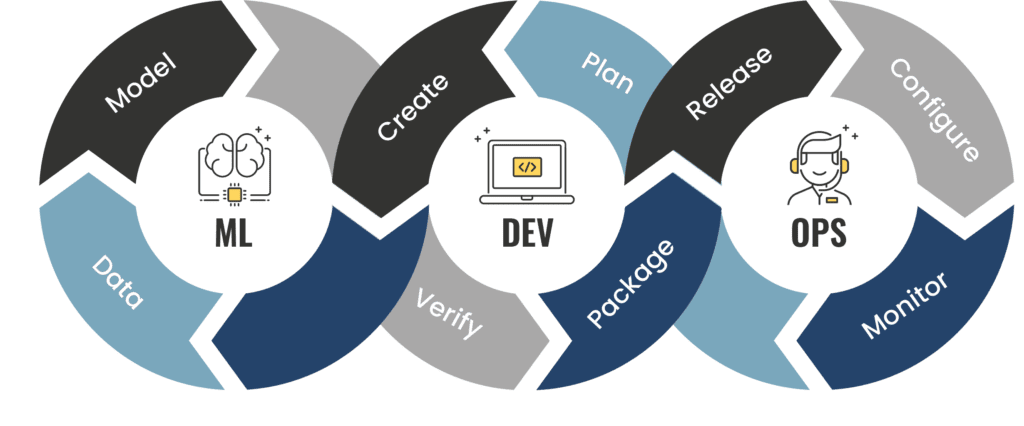
Source : MLOps vs DevOps : What is the difference ? PHDATA.IO (Click on image for link)
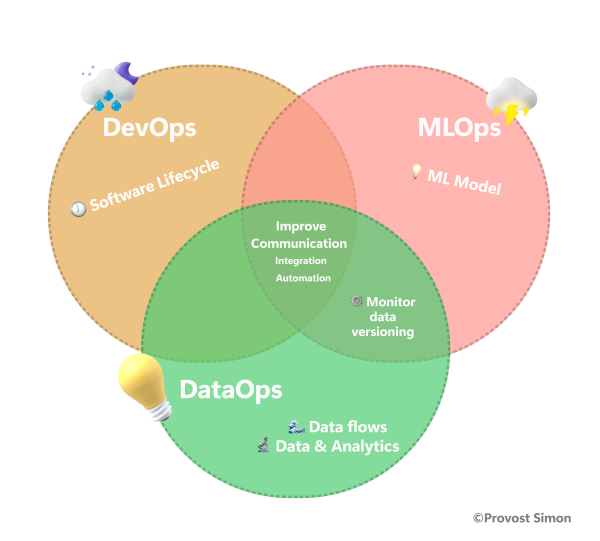
DataOps is a collaborative data management practice focused on improving communication, integration, and automation of data flows between data businesses (Data Engineers) and data consumers (Data Scientists, Business Analysts).
The promise of DataOps is to improve and optimize the life cycle of Data & Analytics projects in terms of speed and quality. Like DevOps, DataOps refocuses your projects on collaboration.
Why do we need MLOps ?
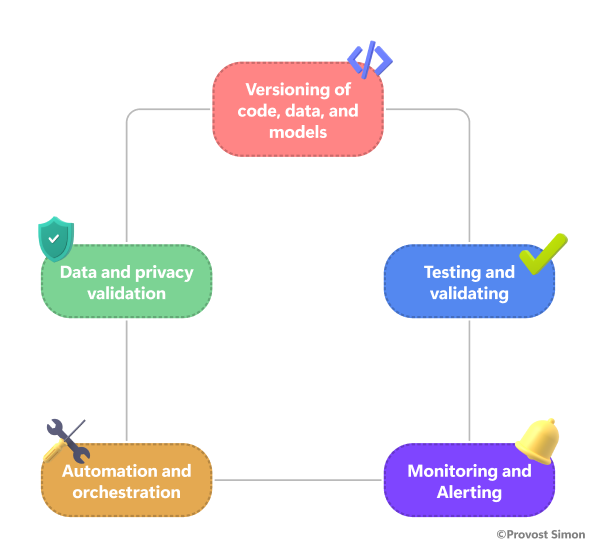
MLOps motto: optimize, accelerate and secure an ML project lifecycle.
This set of best practices will help you with versioning: code, data, models… testing and validation in case of a data drift, or to establish the value of the solution (A/B testing), and ensure the stability of the solution through unit tests for example. It will help us also with monitoring and alerting by understanding models using interpretability and visualizing live metrics. Moreover, MLOps is widely used for automation and orchestration purposes thanks to CI/CD pipelines and DAG orchestration. We could even add things like data and privacy security and budget control.
As a matter of fact, within our data-science team, MLOps tools and practices help us in every step of a Machine Learning project. Starting with logging all the experiments in one comprehensive dashboard makes it easier to compare and choose the best model for a set of metrics that we define to automate its deployment to production and ensure the required tests are in place.
But what if we need to version this model or the data on which it was trained? MLOps can also help with that. In addition, we have been able to easily keep track of the model performances and be alerted in case of a drift.
In a nutshell, using this set of practices help us better organize our ML project and communicate more easily.
Since a picture is word thousand words, here is a graph in attempt to better summarize the concepts addressed above.
In a more practical way, MLOps will help you answer the following questions :
-
How can I be notified as soon as possible whenever my data distributions change?
Things evolve over time, your data too. To name but one example, if you are classifying text using a supervised model, and you start receiving data in a new language unless you detect this change in your data distribution, you will not be able to take this new need into consideration and update your model accordingly. -
How can I track my experiments?
An ML project lifecycle involves multiple phases of experimentations and iterations like testing multiple models, multiple feature selections, hyperparameter tuning… Storing results in Excel sheet plain files will rapidly turn out to be tedious. Fortunately, numerous solutions exist today to track and visualize these experiments. -
How can I easily deploy my model in production?
Once your ML project is approved to be used by the business you need to choose, how are the operations going to use its predictions? A common solution would be to expose these predictions using an API. Some solutions that we will discuss in the next section aim to ease the deployment and shorten the delays. -
How can I make sure that my models are still accurate?
A deterioration in model performances can undermine consumer trust and introduce risk to the business. Therefore, we need to continuously monitor the model behavior and test its predictions.
The faster you detect an eventual problem, the quicker you can remediate it. -
How can I manage the lifecycle of all production models?
Models are bound to change over time. We need to be able to easily retrain a model and update it in production or even plan an automatic retrain with minimal effort. We should also be able to easily manage multiple model versions in production. -
How can we explain the predictions?
In some cases, the operations need to explain the model’s predictions. Depending on which model is being used a range of tools can help clarify its behavior in order to enhance trust in AI.
What tool can be used ?
Numerous methods have been developed in an attempt to encompass everything described above. As a matter of fact, when conducting the search there were much too many to include, so we decided to list the most common ones. Every tool has its functionalities. We attempted to obtain a general benchmark of what each tool accomplishes. We will dive into a more thorough comparison in the next article.
| Tool | Data-versioning | HP Experiment-tracking | Deployement | Model-monitoring | Model-versionning | Model Governance |
| Data Version Control (DVD) | X | |||||
| Pachyderm | X | |||||
| Metaflow | X | X | X | |||
| Kubeflow | X | X | ||||
| MLFlow | X | X | ||||
| Neptune | X | X | X | |||
| Kedro | X | X | X | |||
| Seldon Core | X | X | ||||
| Flyte | X | |||||
| Amazon SageMaker | X | X | X | X | ||
| Weights & Biases | X | X | X |
Conclusion
MLOps is undoubtedly a novel concept, but one that is well justified. It provides organizations with a clear framework for more effective deploying and monitoring machine learning projects to bring business interest back to the forefront of your ML operations. Using these sets of tools and best practices, it becomes easier for data scientists, data engineers, software engineers, and the operations to work and communicate efficiently.
Recent Comments