
La production d’énergie – et plus particulièrement l’ajustement des systèmes de production nécessaire pour répondre à la demande industrielle – représente un défi majeur. Pourquoi ? Du fait du grand nombre de composantes devant être prises en compte : conditions climatiques, nouveaux usages énergétiques, inertie dans les systèmes de production, performances énergétiques, etc. Choisir quels systèmes de production mettre en route (éolien, centrale à gaz, panneaux solaires…), à quel moment et quelle puissance de production leur associer est une tâche complexe, surtout dans le cadre d’un contexte dynamique. Par conséquent, nous avons souhaité valider notre capacité à apporter des solutions permettant d’optimiser l’efficacité d’un ensemble de systèmes de production d’énergie. Systèmes qui doivent répondre à une demande pouvant évoluer au court du temps.
Par Johan JUBLANC, Head of Data chez LittleBigCode
Cet article a donc vocation à démontrer comment nous avons réalisé une première modélisation du problème, les difficultés que nous avons rencontrées et les solutions que nous avons imaginées.
Le problème de départ
Nous avons opté pour la formulation d’un problème simple, mais suffisamment générique pour répondre à un grand nombre de cas d’usage. Nous avons choisi de représenter 3 systèmes de production d’énergie avec des caractéristiques propres, et un plan de production d’énergie réparti sur 24h et établi par le consommateur (demande d’une entreprise par exemple).
Le problème qui se pose est de choisir parmi les 3 sources d’énergie disponibles la meilleure combinaison permettant de maximiser l’efficacité du système à chaque pas de temps (dans ce cas-ci, à chaque heure).

Schéma des systèmes de production et de consommation d’énergie
Voici les différentes composantes du problème :
-
Un agent – le producteur d’énergie – qui doit régler la puissance pour chaque système, à chaque pas de temps et dont l’objectif est d’optimiser l’efficacité de cette combinaison.
-
Une entreprise – le consommateur d’énergie – qui planifie sur 24 heures son besoin d’énergie, sachant que ce plan peut varier au cours de la journée. Mais nous avons estimé qu’il ne peut pas varier moins de 3 heures à l’avance.
Les caractéristiques des systèmes de production
-
Nous avons choisi des caractéristiques simples et fictives, totalement ajustables, pour valider la possibilité de résoudre un problème réaliste :
-
Des caractéristiques de performances en fonction de la puissance délivrée
-
Et les contraintes de mise en route liées au démarrage des systèmes.
Dans cette version basique, les temps de démarrage sont des nombres entiers (1h, 2h ou 3h), mais une adaptation du problème permettrait facilement d’affiner cette contrainte.
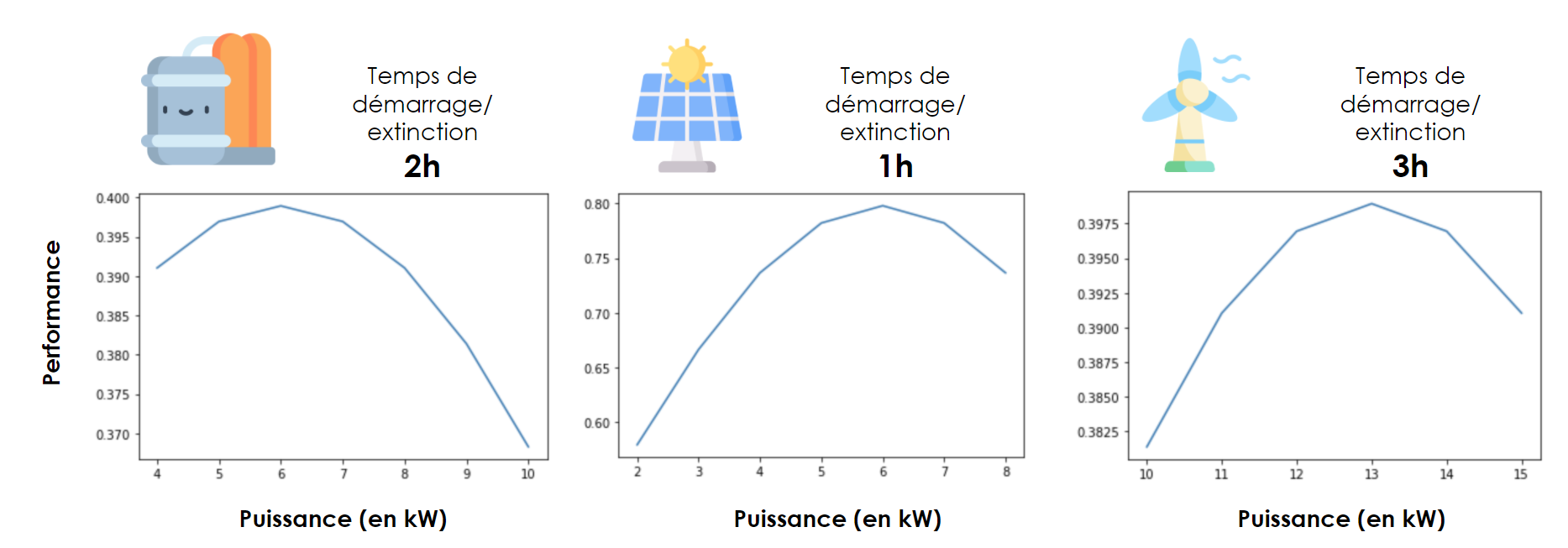
Caractéristiques des systèmes de production
La demande
La demande est présentée sous la forme d’un plan de production aléatoire, variant d’un jour à l’autre et ayant un pas de temps horaire.
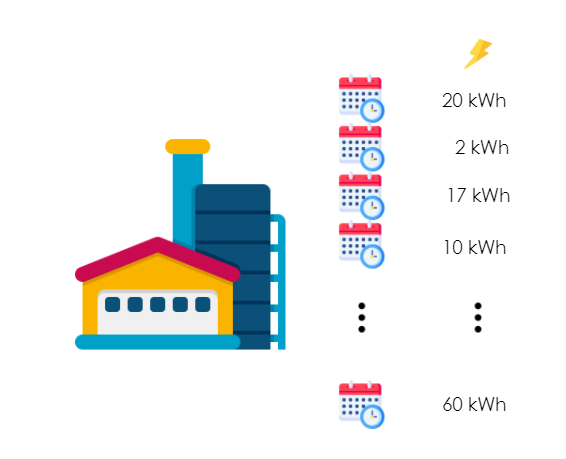
Plan de production
Modélisation des contraintes d’allumages et de démarrage
Afin de rendre compte des contraintes d’allumage et de démarrage, nous avons conçu un état interne du système global. Celui-ci donne le nombre d’heures restant avant qu’un système soit allumé si on l’active maintenant.
Au début de la journée (début de chaque épisode), le compteur de chacun des systèmes est initialisé selon la durée de démarrage.
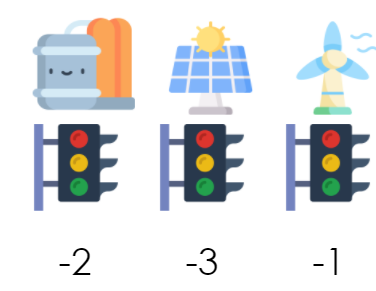
Etat interne d’allumage des systèmes
Ensuite, lorsque l’on règle la puissance de l’un des systèmes sur une valeur strictement positive, il commence alors à démarrer. Puis son compteur augmente de 1 à chaque pas de temps pour lesquels le réglage est strictement positif. Lorsque le système est réglé sur 0, le compteur diminue de 1 et le système commence à s’éteindre.
Un système ne commence à produire de l’énergie que lorsque son compteur est à 0 (il est alors complétement démarré).
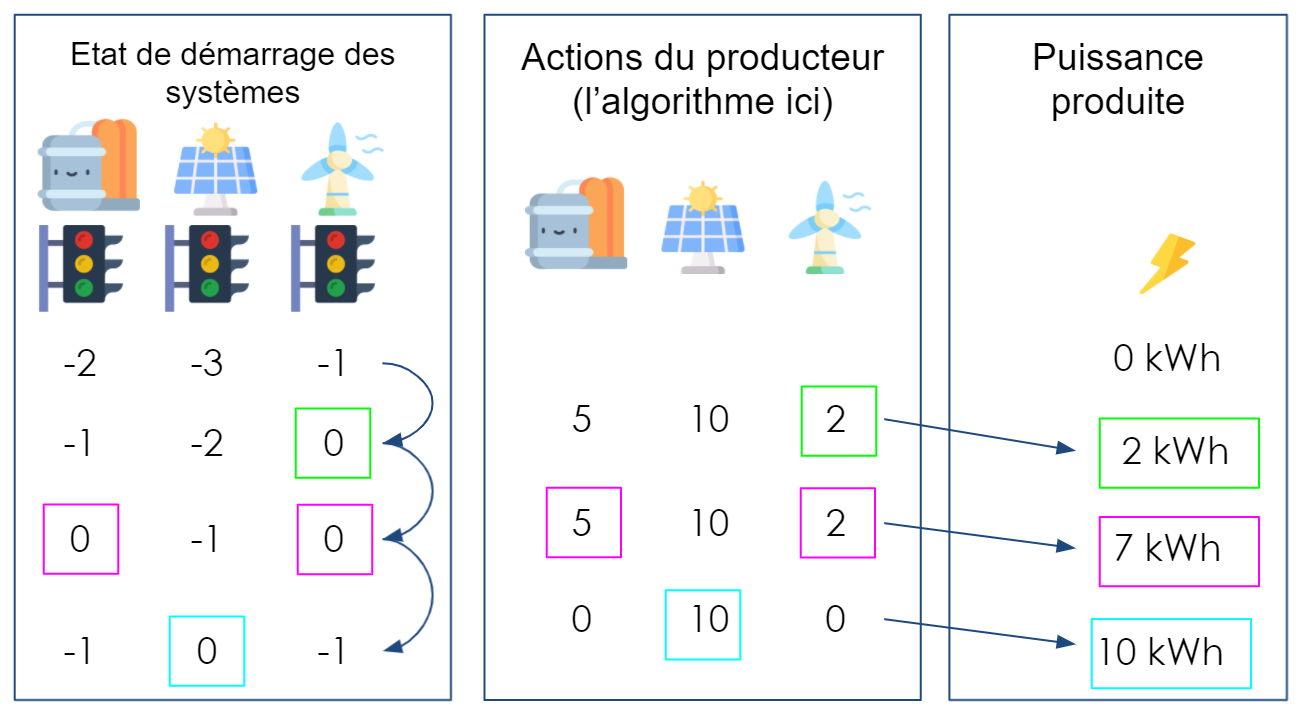
Séquence de décisions et de productions (pas de temps horaire)
Une approche par reinforcement learning
Nous avons modélisé le problème sous la forme de l’interaction entre un agent (le producteur d’énergie) et un environnement représentant le système global (systèmes de production d’énergie et plan de demande).
L’environnement global reçoit à chaque pas de temps les actions de l’agent, c’est-à-dire le réglage pour chaque système de production. Il retourne alors un nouvel état du système global – l’état de démarrage des systèmes de production et la puissance demandée par le consommateur pour les heures à venir -, ainsi qu’une information sur la performance combinée des systèmes de production d’énergie. Celle-ci est considérée comme une récompense (souvent appelée Reward).
L’ensemble des actions (A) possibles pour l’agent (le producteur d’énergie) sont constituées par l’ensemble des combinaisons du réglage de chacun des trois systèmes de production d’énergie, comme expliqué dans l’équation ci-dessous :
![]()
L’ensemble des états (S) possibles renvoyés par l’environnement à l’agent contiennent les états de démarrage des systèmes de production, ainsi que les plans de production d’énergie pour les trois heures à venir :

En formalisant le problème de cette manière, nous pouvons le reformuler comme un processus de décision markovien. Nous pouvons donc tenter de le résoudre avec des algorithmes de reinforcement learning.
Pour pouvoir simuler l’environnement, nous avons choisi de personnaliser un environnement GYM à partir de la class gym.Env. comme dans la capture ci-dessous :
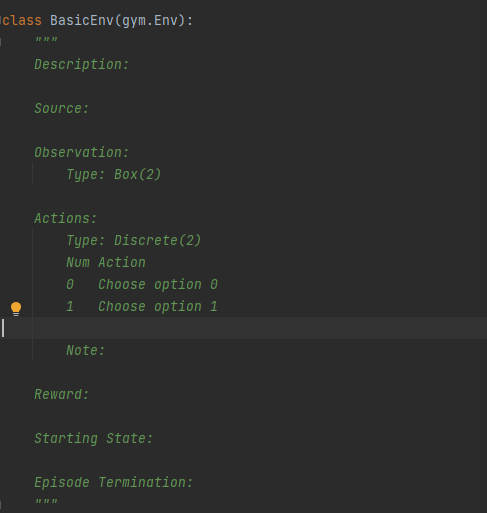
La partie “agent” est en réalité un algorithme de reinforcement learning capable d’apprendre et de prendre des actions. Pour créer cet agent, plusieurs solutions sont disponibles telles que : tensorflow, rl_coach, stablebaseline, etc. Mais les paramètres et le choix de l’algorithme doivent être ajustés pour répondre à notre objectif.
Schéma principal : Reinforcement Learning Coach — Reinforcement Learning Coach 0.12.0 documentation
La construction d’une fonction de récompense permettant l’apprentissage
Une des parties les plus importantes dans l’élaboration d’une solution basée sur du reinforcement learning est de designer correctement la fonction de récompense (fonction de Reward).
Pour permettre à l’algorithme d’apprendre, cette fonction doit avant tout s’avérer pédagogique pour “montrer la voie” à l’agent. En d’autres termes, si la fonction de récompense renvoie systématiquement 0, excepté quand l’agent réalise à la perfection une tâche très complexe, il y a très peu de chance que l’agent apprenne quoi que ce soit.
D’un autre côté, il faut que la fonction de récompense corresponde le mieux possible à l’objectif final de la tâche d’apprentissage. Dans notre cas, cela se complexifie d’autant plus que l’objectif est double :
1/ Premièrement, il s’agit de répondre à la demande ;
2/ Deuxièmement, l’enjeu est d’optimiser la combinaison des systèmes de production pour que le système global soit le plus efficace possible.
Pour représenter ce double objectif, nous avons décomposé la fonction de récompense en 2 parties :
-
[Fournir la puissance planifiée] : on pénalise l’écart entre la puissance produite et la puissance demandée. Plus l’écart est grand en valeur absolue, plus l’action est pénalisée.
![]()
-
[Maximiser l’efficacité total du système de production d’énergie] : si la puissance produite est exactement celle demandée (et seulement dans ce cas), on valorise d’autant plus une combinaison qui maximise la performance moyenne des systèmes.
![]()
Les résultats d’un premier entraînement
Après quelques ajustements, nous avons pu designer un algorithme qui apprend la tâche assignée puisqu’il commence à converger. Il reste toutefois une marge de progression comme le montre la courbe d’évolution des performances :
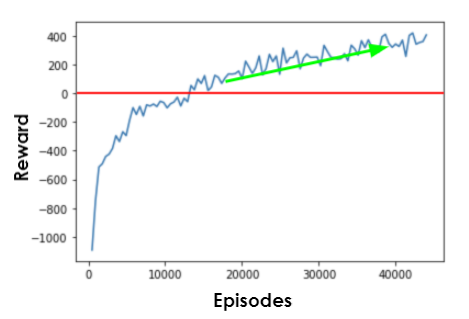
Courbe d’évolution des performances
En analysant un peu plus les résultats, nous constatons que l’algorithme adopte une stratégie permettant de répondre à la demande de puissance ou de s’en approcher : une correction a posteriori permettrait dès à présent de répondre à la demande de manière parfaite.
De plus, nous observons que les performances globales sont relativement élevées et que la stratégie adoptée n’est pas mauvaise.
En revanche, il est probable que nous ne soyons pas encore au niveau optimal car la courbe d’apprentissage n’est pas encore plate.
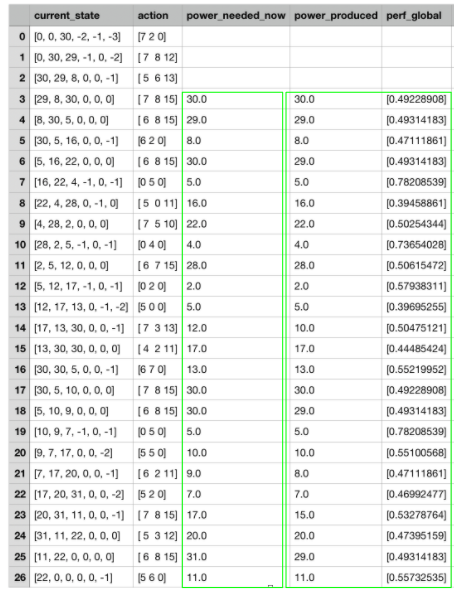
Résultats obtenus
Les perpectives
De nombreux éléments nous encouragent à continuer dans cette voie pour proposer des solutions encore plus performantes.
Tout d’abord, nous avons fait l’effort de créer un problème ayant le potentiel d’être généralisé à des cas complexes. La raison est que nous utilisons des réseaux de neurones profonds comme modèles au cœur de l’algorithme de reinforcement learning (deep reinforcement learning). Il nous semble tout à fait possible d’ajouter / supprimer des systèmes de production, de modifier leurs performances, d’ajouter des contraintes extérieures, etc.
Ensuite, de nombreuses marges de manœuvre existent pour optimiser les paramètres et améliorer la convergence de l’algorithme. Dans un premier temps, on peut réaliser des entraînements plus longs car, en théorie, l’algorithme doit converger pour arriver à l’optimum. La seule question alors est de savoir en combien de temps.
Il est également possible d’envisager de multiples pistes d’optimisation des paramètres du modèle principal, de sa structure, du taux d’apprentissage ou de la stratégie d’exploration pour faire converger l’algorithme plus rapidement. Ces perspectives d’optimisation concernent également le design de la fonction de reward. Celui-ci peut être affiné pour être encore plus pédagogique et faciliter l’apprentissage tout en guidant l’algorithme vers la réalisation de la bonne tâche.
Enfin, les librairies utilisées donnent la possibilité de passer à l’échelle en réalisant des entraînements en parallèle et dans le cloud. Objectif : augmenter la puissance de calcul, affiner la recherche de paramètres et, in fine, améliorer les résultats finaux.
Conclusion
Nous avons cherché à tester une solution de machine learning ayant du potentiel pour combiner plus efficacement des sources d’énergie. Le tout en intégrant des contraintes techniques voire des facteurs exogènes au système d’ensemble, ainsi qu’un aspect dynamique pouvant être pris en compte par le modèle.
Il nous reste encore des étapes à franchir après celle du PoC pour activer une solution sur un cas réel. C’est pourquoi nous recherchons en permanence des partenaires qui souhaitent échanger sur le sujet et susceptibles de nous apporter plus de contexte et d’expertises métier, ou des acteurs s’étant déjà attaqués au même type de problème pour discuter des solutions envisagées et des obstacles rencontrés.
Alors si vous vous intéressez au sujet, n’hésitez pas à nous contacter. Nous serions ravis d’échanger avec vous.
Crédits illustrations : flaticon.com
Recent Comments